Carlo Piccardi
DEIB -
Dipartimento di Elettronica, Informazione e
Bioingegneria
Politecnico
di Milano
Piazza
Leonardo da Vinci 32
20133
Milano, Italy
email
carlo.piccardi@polimi.it
web https://piccardi.faculty.polimi.it
[highlights on recent research]
C. Piccardi, L. Tajoli, The
rise and fall of nations: evolving roles in
the international trade networks, Journal
of Complex Networks, 14(3),
cnag016(1-25), 2026. [doi]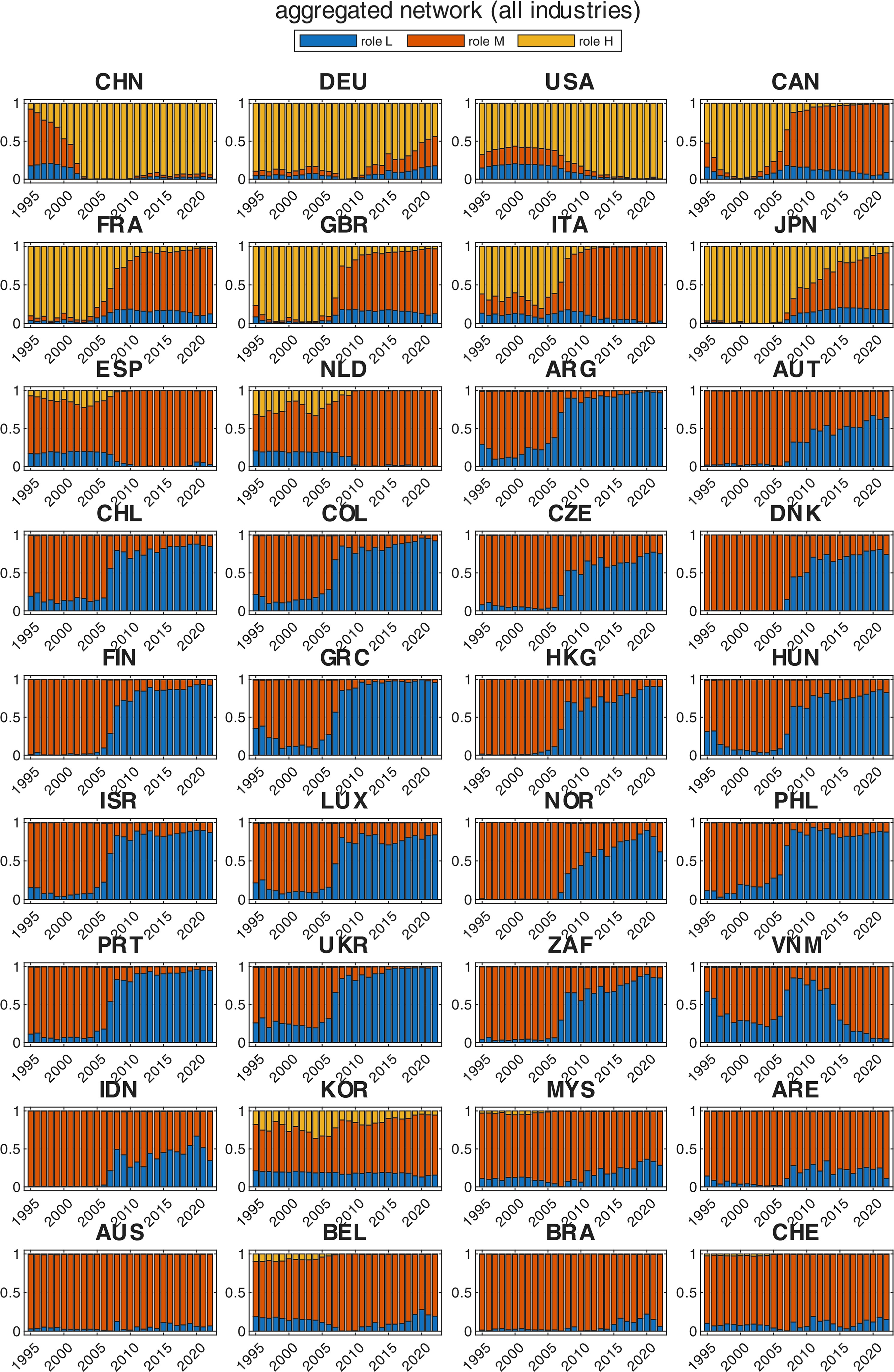 In this paper, we apply
a role classification method to
international trade networks derived
from the OECD-ICIO dataset. Each node
in the network corresponds to a
country in the dataset and is
associated with a feature vector based
on network centrality indicators.
After reducing redundant information
via principal component analysis, we
group countries using fuzzy
clustering. This defines distinct
roles, to which each country belongs
with an appropriate membership level.
Our analysis then focuses on how each
country’s role in the international
production and trade network has
evolved between 1995 and 2022 and the
related economic implications. The
results show that, while many
countries (such as the USA and
Germany) have essentially maintained
their position over time, many others
have changed dramatically. For
instance, although at different
levels, China and Vietnam have
transitioned to higher-level roles,
whereas the United Kingdom, Japan and
Italy, among others, have deteriorated
from leader to second-tier country
status. Interestingly, a sharp
downgrading of role can occur even
when economic and network indicators
undergo only modest changes, if
competing countries increase their
performance disproportionately. The
work concludes with a separate
analysis of some of the most important
goods and services sectors. Overall,
the results reveal growing
polarization, with a small number of
leading countries progressively moving
away from the rest of the world in
terms of economic dominance. In this paper, we apply
a role classification method to
international trade networks derived
from the OECD-ICIO dataset. Each node
in the network corresponds to a
country in the dataset and is
associated with a feature vector based
on network centrality indicators.
After reducing redundant information
via principal component analysis, we
group countries using fuzzy
clustering. This defines distinct
roles, to which each country belongs
with an appropriate membership level.
Our analysis then focuses on how each
country’s role in the international
production and trade network has
evolved between 1995 and 2022 and the
related economic implications. The
results show that, while many
countries (such as the USA and
Germany) have essentially maintained
their position over time, many others
have changed dramatically. For
instance, although at different
levels, China and Vietnam have
transitioned to higher-level roles,
whereas the United Kingdom, Japan and
Italy, among others, have deteriorated
from leader to second-tier country
status. Interestingly, a sharp
downgrading of role can occur even
when economic and network indicators
undergo only modest changes, if
competing countries increase their
performance disproportionately. The
work concludes with a separate
analysis of some of the most important
goods and services sectors. Overall,
the results reveal growing
polarization, with a small number of
leading countries progressively moving
away from the rest of the world in
terms of economic dominance. |
|
F. Mazza, M. Brambilla, C. Piccardi, and F. Pierri, A data-driven analysis of the impact of non-compliant individuals on epidemic diffusion in urban settings, Proceedings of the Royal Society A, 481, 20250511, 2025. [doi] 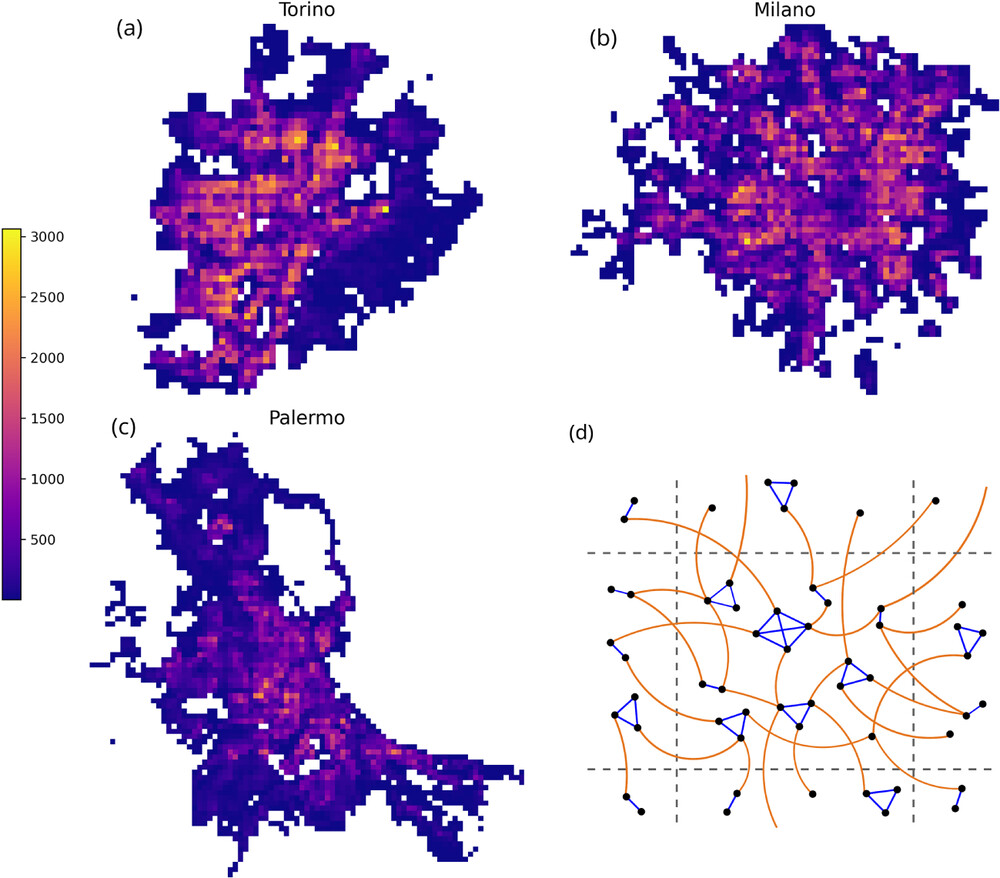 Individuals who do not
comply with public health safety
measures pose a significant challenge
to effective epidemic control, as
their risky behaviours can undermine
public health interventions. This is
particularly relevant in urban
environments because of their high
population density and complex social
interactions. In this study, we employ
detailed contact networks, built using
a data-driven approach, to examine the
impact of non-compliant individuals on
epidemic dynamics in three major
Italian cities: Torino, Milano and
Palermo. We use a heterogeneous
extension of the
susceptible–infected–recovered (SIR)
model that distinguishes between
ordinary and non-compliant
individuals, who are more infectious
and/or more susceptible. By combining
electoral data with recent findings on
vaccine hesitancy, we obtain spatially
heterogeneous distributions of
non-compliance. Epidemic simulations
demonstrate that even a small
proportion of non-compliant
individuals in the population can
substantially increase the number of
infections and accelerate the timing
of their peak. Furthermore, the impact
of non-compliance is greatest when
disease transmission rates are
moderate. Including the heterogeneous,
data-driven distribution of
non-compliance in the simulation
results in infection hotspots forming
with varying intensity according to
the disease transmission rate.
Overall, these findings emphasize the
importance of monitoring behavioural
compliance and tailoring public health
interventions to address localized
risks. Individuals who do not
comply with public health safety
measures pose a significant challenge
to effective epidemic control, as
their risky behaviours can undermine
public health interventions. This is
particularly relevant in urban
environments because of their high
population density and complex social
interactions. In this study, we employ
detailed contact networks, built using
a data-driven approach, to examine the
impact of non-compliant individuals on
epidemic dynamics in three major
Italian cities: Torino, Milano and
Palermo. We use a heterogeneous
extension of the
susceptible–infected–recovered (SIR)
model that distinguishes between
ordinary and non-compliant
individuals, who are more infectious
and/or more susceptible. By combining
electoral data with recent findings on
vaccine hesitancy, we obtain spatially
heterogeneous distributions of
non-compliance. Epidemic simulations
demonstrate that even a small
proportion of non-compliant
individuals in the population can
substantially increase the number of
infections and accelerate the timing
of their peak. Furthermore, the impact
of non-compliance is greatest when
disease transmission rates are
moderate. Including the heterogeneous,
data-driven distribution of
non-compliance in the simulation
results in infection hotspots forming
with varying intensity according to
the disease transmission rate.
Overall, these findings emphasize the
importance of monitoring behavioural
compliance and tailoring public health
interventions to address localized
risks. |
|
C. Piccardi, An egonet-based approach to effective weighted network comparison, Scientific Reports, 15, 23291, 2025. [doi] 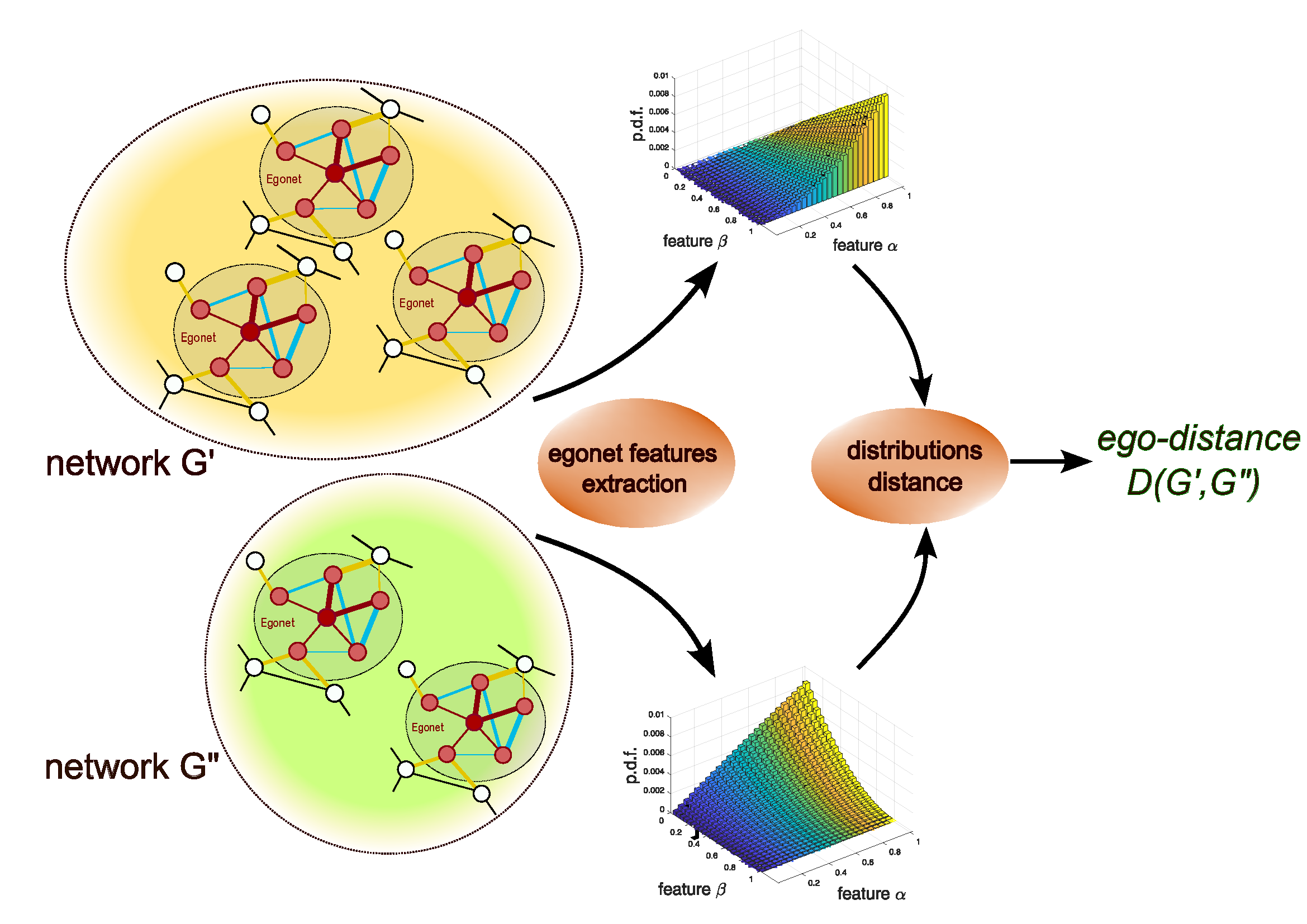 With the
impressive growth of network models in
practically every scientific and
technological area, we are often faced
with the need to compare graphs, i.e.,
to quantify their (dis)similarity
using appropriate metrics. This is
necessary, for example, to identify
networks with comparable
characteristics or to spot anomalous
instants in a time sequence of graphs.
While a large number of metrics are
available for binary networks, the set
of comparison methods capable of
handling weighted graphs is much
smaller. Yet, the strength of
connections is often a key ingredient
of the model, and ignoring this
information could lead to misleading
results. In this paper we introduce a
family of dissimilarity measures to
compare undirected weighted networks.
They fall into the class of
alignment-free metrics: as such, they
do not require the correspondence of
the nodes between the two graphs and
can also compare networks of different
sizes. In short, they are based on the
distributions, on the graph, of a few
egonet features which are easily
defined and computed: the distance
between two graphs is then the
distance between the corresponding
distributions. On a properly defined
testbed with a pool of weighted
network models with diversified
characteristics, the proposed metrics
are shown to achieve state-of-the-art
performance in the model
classification task. The effectiveness
and applicability of the proposed
metrics are then demonstrated on two
examples. In the first, some
''filtering'' schemes -- designed to
eliminate non-significant links while
maintaining most of the total weight
-- are evaluated in their ability to
produce as output a graph faithful to
the original, in terms of the local
structure around nodes. In the second
example, analyzing a timeline of stock
market correlation graphs highlights
anomalies associated with periods of
financial instability. With the
impressive growth of network models in
practically every scientific and
technological area, we are often faced
with the need to compare graphs, i.e.,
to quantify their (dis)similarity
using appropriate metrics. This is
necessary, for example, to identify
networks with comparable
characteristics or to spot anomalous
instants in a time sequence of graphs.
While a large number of metrics are
available for binary networks, the set
of comparison methods capable of
handling weighted graphs is much
smaller. Yet, the strength of
connections is often a key ingredient
of the model, and ignoring this
information could lead to misleading
results. In this paper we introduce a
family of dissimilarity measures to
compare undirected weighted networks.
They fall into the class of
alignment-free metrics: as such, they
do not require the correspondence of
the nodes between the two graphs and
can also compare networks of different
sizes. In short, they are based on the
distributions, on the graph, of a few
egonet features which are easily
defined and computed: the distance
between two graphs is then the
distance between the corresponding
distributions. On a properly defined
testbed with a pool of weighted
network models with diversified
characteristics, the proposed metrics
are shown to achieve state-of-the-art
performance in the model
classification task. The effectiveness
and applicability of the proposed
metrics are then demonstrated on two
examples. In the first, some
''filtering'' schemes -- designed to
eliminate non-significant links while
maintaining most of the total weight
-- are evaluated in their ability to
produce as output a graph faithful to
the original, in terms of the local
structure around nodes. In the second
example, analyzing a timeline of stock
market correlation graphs highlights
anomalies associated with periods of
financial instability.Matlab code of the EgoDistW function and network data used in the paper are available here. |
|
C. Piccardi, L. Tajoli, and R. Vitali, Patterns of variability in the structure of global value chains: a network analysis, Review of World Economics, 160, 1009-1036, 2024. [doi]  Global Value Chains
(GVCs) are a feature of the organization
of production in many sectors and
countries and they deeply affect
international trade patterns. How far
the separation of production
stages—generating increasingly
widespread GVCs—can go, is currently a
matter of debate. The main focus of this
paper is to investigate GVCs at the
country-industry level by modelling them
through the construction of a specific
network and using network analysis
tools. In particular, the aim is to
propose a network-based measure of GVCs
length to assess whether the structure
of GVCs has stretched or shrank over
time. Analyzing the evolution of these
structures is important to better
understand the role played by countries
in the production chain, with
implications also for their fragility or
resilience in presence of external
shocks. Our measure allows to consider
differently shaped GVCs, and the results
show that there are relevant differences
among sectors and countries in terms of
the evolution of GVCs, especially
considering direct or indirect links.
Overall, we find a general stability
over time of GVCs, confirming the
importance of the “relational approach”
in GVCs. But the shifts in the
geographical patterns of the connections
also support the view that firms
organizing this complex form of
production are ready to grasp better
opportunities when they appear in the
global markets. Global Value Chains
(GVCs) are a feature of the organization
of production in many sectors and
countries and they deeply affect
international trade patterns. How far
the separation of production
stages—generating increasingly
widespread GVCs—can go, is currently a
matter of debate. The main focus of this
paper is to investigate GVCs at the
country-industry level by modelling them
through the construction of a specific
network and using network analysis
tools. In particular, the aim is to
propose a network-based measure of GVCs
length to assess whether the structure
of GVCs has stretched or shrank over
time. Analyzing the evolution of these
structures is important to better
understand the role played by countries
in the production chain, with
implications also for their fragility or
resilience in presence of external
shocks. Our measure allows to consider
differently shaped GVCs, and the results
show that there are relevant differences
among sectors and countries in terms of
the evolution of GVCs, especially
considering direct or indirect links.
Overall, we find a general stability
over time of GVCs, confirming the
importance of the “relational approach”
in GVCs. But the shifts in the
geographical patterns of the connections
also support the view that firms
organizing this complex form of
production are ready to grasp better
opportunities when they appear in the
global markets.
|
|
P. Bolzern, A. Colombo, and C. Piccardi, Manipulating opinions in social networks with community structure, IEEE Transactions on Network Science and Engineering, 11(1), 185-196, 2024. [doi] 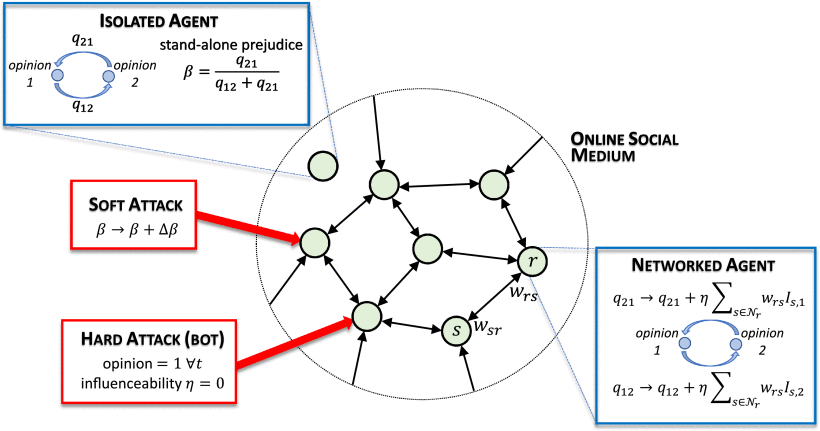 Online
social media have been one of the
greatest drivers of societal change of
the past two decades, but are now being
recognized as one of the major causes of
opinion radicalization and one of the
most effective tools for opinion
manipulation. Starting from a class of
stochastic models of opinion dynamics,
and considering different structures of
social networks with increasingly
realistic features (including a snapshot
of the Facebook friendship network), we
develop a mathematical model of
different forms of opinion manipulation.
We then explore how network properties,
and in particular degree distribution
and community structure, interact with
the attack to amplify or reduce its
effect on the population, both globally
and on specific subsets. We find, in
particular, that degree heterogeneity is
key to making online social media
susceptible to very effective attacks,
even with relatively little effort.
Communities instead play a more complex
role, acting both as barriers to the
spread of manipulated opinions through
the whole population and as amplifiers
of manipulated opinions when the target
of the attack is a community of the
online social medium. The results of our
study can help design effective
strategies to prevent the manipulation
of opinions through online social media. Online
social media have been one of the
greatest drivers of societal change of
the past two decades, but are now being
recognized as one of the major causes of
opinion radicalization and one of the
most effective tools for opinion
manipulation. Starting from a class of
stochastic models of opinion dynamics,
and considering different structures of
social networks with increasingly
realistic features (including a snapshot
of the Facebook friendship network), we
develop a mathematical model of
different forms of opinion manipulation.
We then explore how network properties,
and in particular degree distribution
and community structure, interact with
the attack to amplify or reduce its
effect on the population, both globally
and on specific subsets. We find, in
particular, that degree heterogeneity is
key to making online social media
susceptible to very effective attacks,
even with relatively little effort.
Communities instead play a more complex
role, acting both as barriers to the
spread of manipulated opinions through
the whole population and as amplifiers
of manipulated opinions when the target
of the attack is a community of the
online social medium. The results of our
study can help design effective
strategies to prevent the manipulation
of opinions through online social media.
|
|
A. Radici, J. Claudet, A. Ligas, I. Bitetto, G. Lembo, M.T. Spedicato, P. Sartor, C. Piccardi, and P. Melià, Assessing fish–fishery dynamics from a spatially explicit metapopulation perspective reveals winners and losers in fisheries management, Journal of Applied Ecology, 60, 2482-2493, 2023. [doi]  Sustainable
management of living resources must
reconcile biodiversity conservation and
socioeconomic viability of human
activities. In the case of fisheries,
sustainable management design is made
challenging by the complex
spatiotemporal interactions between fish
and fisheries. We develop a
comprehensive metapopulation framework
integrating data on species life-history
traits, connectivity and habitat
distribution to identify priority areas
for fishing regulation and assess how
management impacts are spatially
distributed. We trial this approach on
European hake fisheries in the
north-western Mediterranean, where we
assess area-based management scenarios
in terms of stock status and fishery
productivity to prioritize areas for
protection. Model simulations show that
local fishery closures have the
potential to enhance both spawning stock
biomass and landings on a regional scale
compared to a status quo scenario, but
that improving protection is easier than
increasing productivity. Moreover, the
interaction between metapopulation
dynamics and the redistribution of
fishing effort following local closures
implies that benefits and drawbacks are
heterogeneously distributed in space,
the former being concentrated in the
proximity of the protected site. A
network analysis shows that priority
areas for protection are those with the
highest connectivity (as expressed by
network metrics) if the objective is to
improve the spawning stock, while no
significant relationship emerges between
connectivity and potential for increased
landings. Synthesis and applications.
Our framework provides a tool for (1)
assessing area-based management measures
aimed at improving fisheries outcomes in
terms of both conservation and
socioeconomic viability and (2)
describing the spatial distribution of
costs and benefits, which can help guide
effective management and gain
stakeholder support. Adult dispersal
remains the main source of uncertainty
that needs to be investigated to
effectively apply our model to fisheries
regulation. Sustainable
management of living resources must
reconcile biodiversity conservation and
socioeconomic viability of human
activities. In the case of fisheries,
sustainable management design is made
challenging by the complex
spatiotemporal interactions between fish
and fisheries. We develop a
comprehensive metapopulation framework
integrating data on species life-history
traits, connectivity and habitat
distribution to identify priority areas
for fishing regulation and assess how
management impacts are spatially
distributed. We trial this approach on
European hake fisheries in the
north-western Mediterranean, where we
assess area-based management scenarios
in terms of stock status and fishery
productivity to prioritize areas for
protection. Model simulations show that
local fishery closures have the
potential to enhance both spawning stock
biomass and landings on a regional scale
compared to a status quo scenario, but
that improving protection is easier than
increasing productivity. Moreover, the
interaction between metapopulation
dynamics and the redistribution of
fishing effort following local closures
implies that benefits and drawbacks are
heterogeneously distributed in space,
the former being concentrated in the
proximity of the protected site. A
network analysis shows that priority
areas for protection are those with the
highest connectivity (as expressed by
network metrics) if the objective is to
improve the spawning stock, while no
significant relationship emerges between
connectivity and potential for increased
landings. Synthesis and applications.
Our framework provides a tool for (1)
assessing area-based management measures
aimed at improving fisheries outcomes in
terms of both conservation and
socioeconomic viability and (2)
describing the spatial distribution of
costs and benefits, which can help guide
effective management and gain
stakeholder support. Adult dispersal
remains the main source of uncertainty
that needs to be investigated to
effectively apply our model to fisheries
regulation. |
|
C. Piccardi, Metrics for network comparison using egonet feature distribution, Scientific Reports, 13, 14657, 2023. [doi] 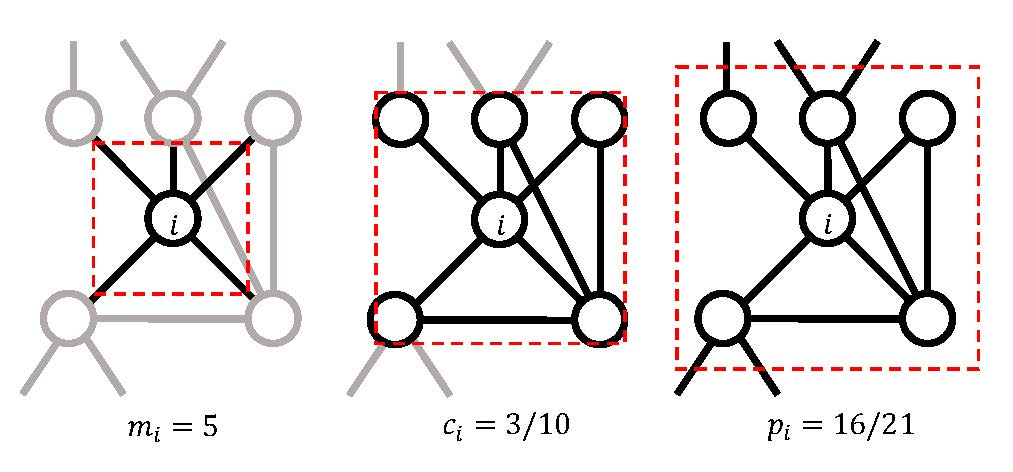 Identifying
networks with similar characteristics in
a given ensemble, or detecting pattern
discontinuities in a temporal sequence
of networks, are two examples of tasks
that require an effective metric capable
of quantifying network (dis)similarity.
Here we propose a method based on a
global portrait of graph properties
built by processing local nodes
features. More precisely, a set of
dissimilarity measures is defined by
elaborating the distributions, over the
network, of a few egonet features,
namely the degree, the clustering
coefficient, and the egonet persistence.
The method, which does not require the
alignment of the two networks being
compared, exploits the statistics of the
three features to define one- or
multi-dimensional distribution
functions, which are then compared to
define a distance between the networks.
The effectiveness of the method is
evaluated using a standard
classification test, i.e., recognizing
the graphs originating from the same
synthetic model. Overall, the proposed
distances have performances comparable
to the best state-of-the-art techniques
(graphlet-based methods) with similar
computational requirements. Given its
simplicity and flexibility, the method
is proposed as a viable approach for
network comparison tasks. Identifying
networks with similar characteristics in
a given ensemble, or detecting pattern
discontinuities in a temporal sequence
of networks, are two examples of tasks
that require an effective metric capable
of quantifying network (dis)similarity.
Here we propose a method based on a
global portrait of graph properties
built by processing local nodes
features. More precisely, a set of
dissimilarity measures is defined by
elaborating the distributions, over the
network, of a few egonet features,
namely the degree, the clustering
coefficient, and the egonet persistence.
The method, which does not require the
alignment of the two networks being
compared, exploits the statistics of the
three features to define one- or
multi-dimensional distribution
functions, which are then compared to
define a distance between the networks.
The effectiveness of the method is
evaluated using a standard
classification test, i.e., recognizing
the graphs originating from the same
synthetic model. Overall, the proposed
distances have performances comparable
to the best state-of-the-art techniques
(graphlet-based methods) with similar
computational requirements. Given its
simplicity and flexibility, the method
is proposed as a viable approach for
network comparison tasks.Matlab code of the EgoDist function and network data used in the paper are available at GitHub and at MathWorks File Exchange. |
|
V.P. Hoang, C. Piccardi, L. Tajoli, Reshaping the structure of the World Trade Network: a pivotal role for China?, Applied Network Science, 8, 35, 2023. [doi]  In
recent years, the global
trade landscape has
undergone significant
changes, particularly in the
aftermath of the 2008
financial crisis and more
recently as a consequence of
Covid-19 pandemic. To
understand the structure of
international trade and the
impact of these changes,
this study applies a
combination of network
analysis and causal
inference techniques to the
most extensive coverage of
available data in terms of
time span and spatial
extension. The study is
conducted in two phases. The
first one explores the
structure of international
trade by providing a
comprehensive analysis of
the World Trade Network
(WTN) from various
perspectives, including the
identification of key
players and clusters of
strongly interacting
countries. The second phase
investigates the impact of
the rising role of China on
the global structure of the
WTN. Overall, the results
highlight a structural
change in the WTN, evidenced
by a variety of network
metrics, around China’s
rapid growth years.
Additionally, the reshaping
of the WTN is not only
accompanied by a significant
increase in trade flows
between China and its
partners, but also by a
corresponding decline in
trade among
non-China-partner countries.
These results suggest that
China played a pivotal role
in the restructuring of the
WTN in the first decades of
this century. The findings
of this study shed light on
the interpretation of the
rapidly changing landscape
of global trade. In
recent years, the global
trade landscape has
undergone significant
changes, particularly in the
aftermath of the 2008
financial crisis and more
recently as a consequence of
Covid-19 pandemic. To
understand the structure of
international trade and the
impact of these changes,
this study applies a
combination of network
analysis and causal
inference techniques to the
most extensive coverage of
available data in terms of
time span and spatial
extension. The study is
conducted in two phases. The
first one explores the
structure of international
trade by providing a
comprehensive analysis of
the World Trade Network
(WTN) from various
perspectives, including the
identification of key
players and clusters of
strongly interacting
countries. The second phase
investigates the impact of
the rising role of China on
the global structure of the
WTN. Overall, the results
highlight a structural
change in the WTN, evidenced
by a variety of network
metrics, around China’s
rapid growth years.
Additionally, the reshaping
of the WTN is not only
accompanied by a significant
increase in trade flows
between China and its
partners, but also by a
corresponding decline in
trade among
non-China-partner countries.
These results suggest that
China played a pivotal role
in the restructuring of the
WTN in the first decades of
this century. The findings
of this study shed light on
the interpretation of the
rapidly changing landscape
of global trade. |
|
L. Tajoli, F. Airoldi, and C. Piccardi, The network of international trade in services, Applied Network Science, 6, 68, 2021. [doi] 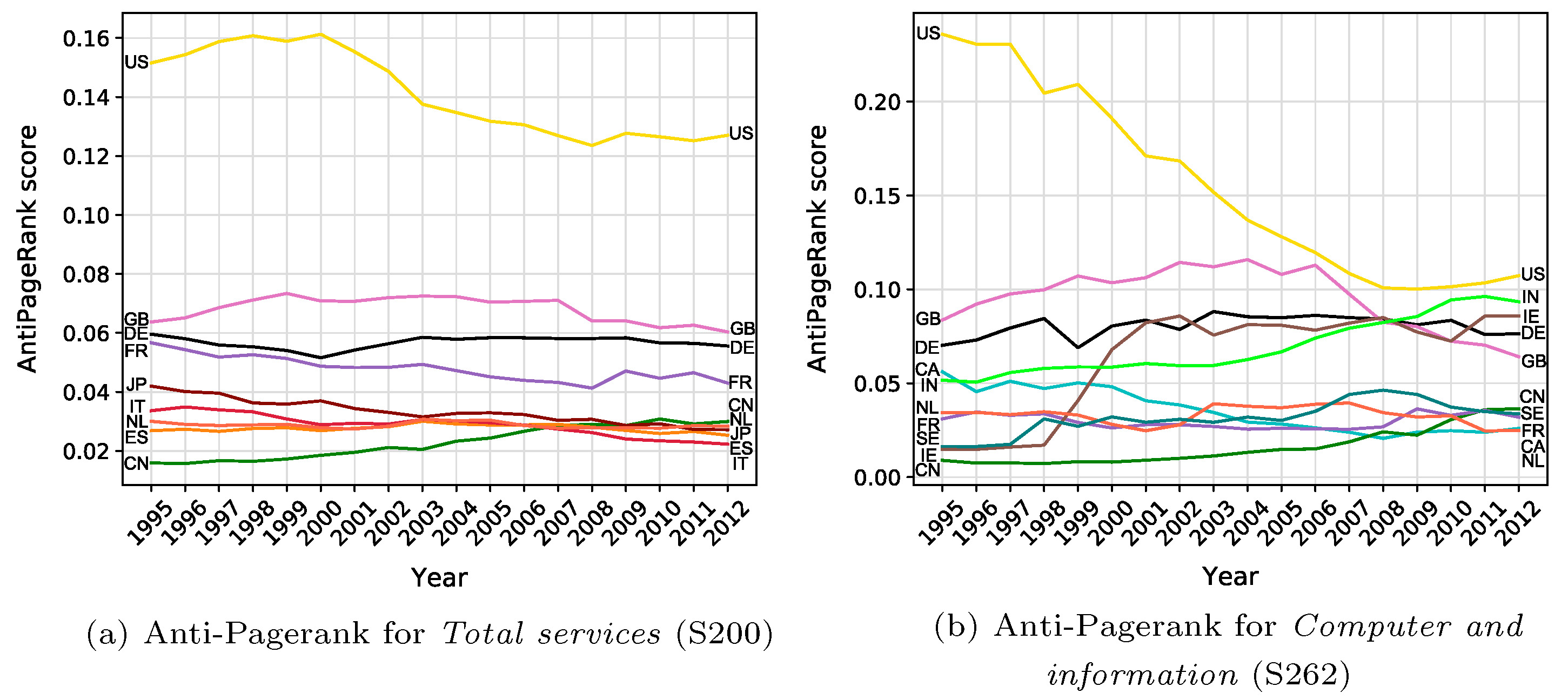 While the
share of services in international trade
has been increasing very slowly over the
years, oscillating around 20 per cent
since the 1990s, their role has
constantly gained importance. Trade in
services certainly faces many more
obstacles than trade in goods, but its
impact on globalization and countries’
competitiveness is crucial, and it is
therefore worth investigating its
characteristics. The present work aims
to analyse the networks of international
trade in services and to unveil specific
properties by exploiting a number of
existing methodologies and algorithms.
After describing the global properties
of the networks of the various service
classes, we investigate differences and
similarities among them, and we
highlight the most influential countries
in the trade of specific services. We
find that traded services display
sharply different characteristics and
they can be grouped in two different
sets according to their network
structures. Countries’ positions in
these networks are diversified, with
connections unevenly distributed,
especially for some service categories.
We discover that the structure of links,
i.e. the topology of the networks,
identifies the role of countries much
more clearly than the sole amount of
services traded. Overall, the results
highlight important features, as well as
changes over time, in the landscape of
the international services. While the
share of services in international trade
has been increasing very slowly over the
years, oscillating around 20 per cent
since the 1990s, their role has
constantly gained importance. Trade in
services certainly faces many more
obstacles than trade in goods, but its
impact on globalization and countries’
competitiveness is crucial, and it is
therefore worth investigating its
characteristics. The present work aims
to analyse the networks of international
trade in services and to unveil specific
properties by exploiting a number of
existing methodologies and algorithms.
After describing the global properties
of the networks of the various service
classes, we investigate differences and
similarities among them, and we
highlight the most influential countries
in the trade of specific services. We
find that traded services display
sharply different characteristics and
they can be grouped in two different
sets according to their network
structures. Countries’ positions in
these networks are diversified, with
connections unevenly distributed,
especially for some service categories.
We discover that the structure of links,
i.e. the topology of the networks,
identifies the role of countries much
more clearly than the sole amount of
services traded. Overall, the results
highlight important features, as well as
changes over time, in the landscape of
the international services.
|
|
P. Finotelli, C. Piccardi, E. Miglio, and P. Dulio, A graphlet-based topological characterization of the resting-state network in healthy people, Frontiers in Neuroscience, 15, 665544, 2021. [doi] 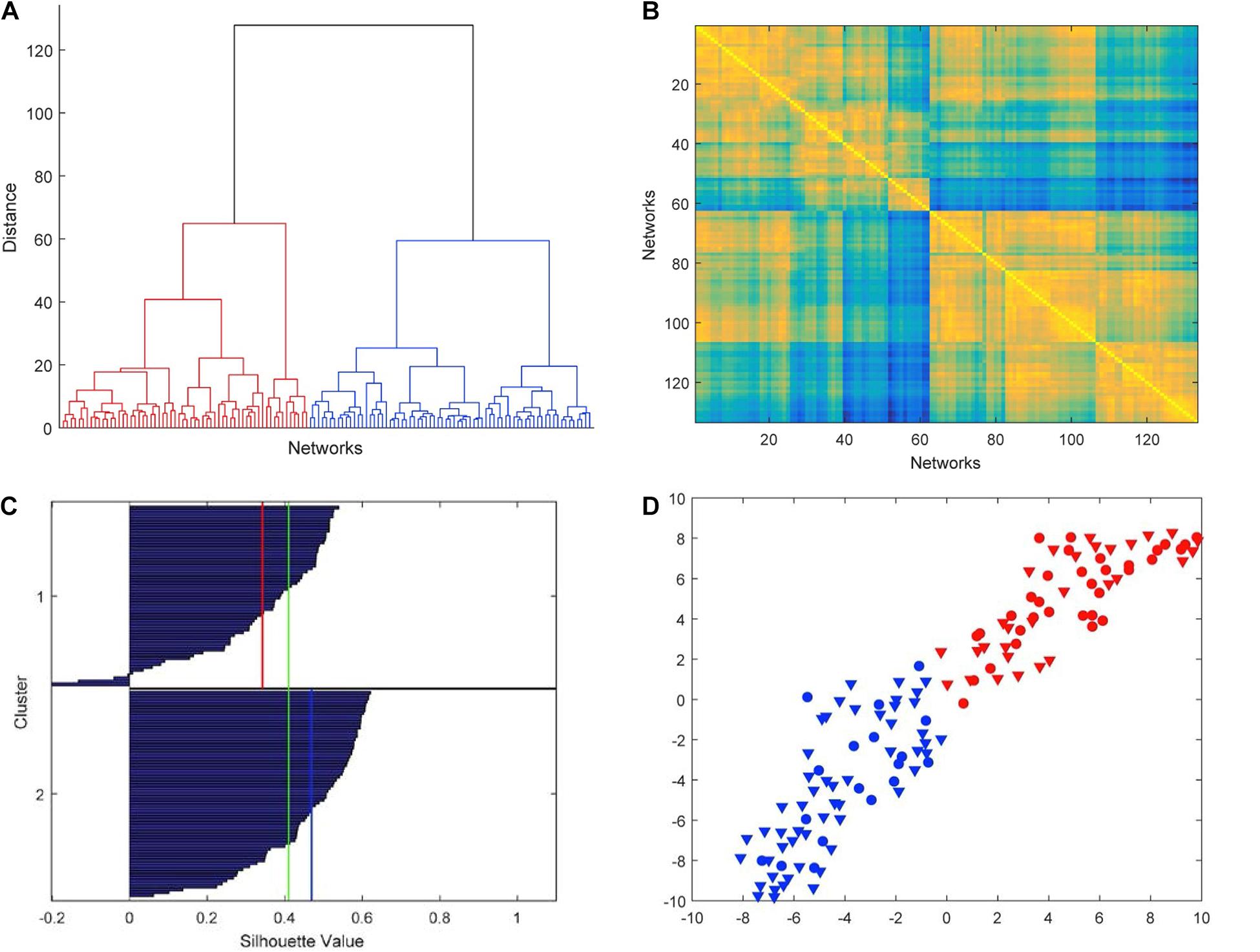 In this
paper, we propose a graphlet-based
topological algorithm for the
investigation of the brain network at
resting state (RS). To this aim, we
model the brain as a graph, where
(labeled) nodes correspond to specific
cerebral areas and links are weighted
connections determined by the intensity
of the functional magnetic resonance
imaging (fMRI). Then, we select a number
of working graphlets, namely, connected
and non-isomorphic induced subgraphs. We
compute, for each labeled node, its
Graphlet Degree Vector (GDV), which
allows us to associate a GDV matrix to
each one of the 133 subjects of the
considered sample, reporting how many
times each node of the atlas “touches”
the independent orbits defined by the
graphlet set. We focus on the 56
independent columns (i.e., non-redundant
orbits) of the GDV matrices. By
aggregating their count all over the 133
subjects and then by sorting each column
independently, we obtain a sorted node
table, whose top-level entries highlight
the nodes (i.e., brain regions) most
frequently touching each of the 56
independent graphlet orbits. Then, by
pairwise comparing the columns of the
sorted node table in the top-k entries
for various values of k, we identify
sets of nodes that are consistently
involved with high frequency in the 56
independent graphlet orbits all over the
133 subjects. It turns out that these
sets consist of labeled nodes directly
belonging to the default mode network
(DMN) or strongly interacting with it at
the RS, indicating that graphlet
analysis provides a viable tool for the
topological characterization of such
brain regions. We finally provide a
validation of the graphlet approach by
testing its power in catching network
differences. To this aim, we encode in a
Graphlet Correlation Matrix (GCM) the
network information associated with each
subject then construct a
subject-to-subject Graphlet Correlation
Distance (GCD) matrix based on the
Euclidean distances between all possible
pairs of GCM. The analysis of the
clusters induced by the GCD matrix shows
a clear separation of the subjects in
two groups, whose relationship with the
subject characteristics is investigated. In this
paper, we propose a graphlet-based
topological algorithm for the
investigation of the brain network at
resting state (RS). To this aim, we
model the brain as a graph, where
(labeled) nodes correspond to specific
cerebral areas and links are weighted
connections determined by the intensity
of the functional magnetic resonance
imaging (fMRI). Then, we select a number
of working graphlets, namely, connected
and non-isomorphic induced subgraphs. We
compute, for each labeled node, its
Graphlet Degree Vector (GDV), which
allows us to associate a GDV matrix to
each one of the 133 subjects of the
considered sample, reporting how many
times each node of the atlas “touches”
the independent orbits defined by the
graphlet set. We focus on the 56
independent columns (i.e., non-redundant
orbits) of the GDV matrices. By
aggregating their count all over the 133
subjects and then by sorting each column
independently, we obtain a sorted node
table, whose top-level entries highlight
the nodes (i.e., brain regions) most
frequently touching each of the 56
independent graphlet orbits. Then, by
pairwise comparing the columns of the
sorted node table in the top-k entries
for various values of k, we identify
sets of nodes that are consistently
involved with high frequency in the 56
independent graphlet orbits all over the
133 subjects. It turns out that these
sets consist of labeled nodes directly
belonging to the default mode network
(DMN) or strongly interacting with it at
the RS, indicating that graphlet
analysis provides a viable tool for the
topological characterization of such
brain regions. We finally provide a
validation of the graphlet approach by
testing its power in catching network
differences. To this aim, we encode in a
Graphlet Correlation Matrix (GCM) the
network information associated with each
subject then construct a
subject-to-subject Graphlet Correlation
Distance (GCD) matrix based on the
Euclidean distances between all possible
pairs of GCM. The analysis of the
clusters induced by the GCD matrix shows
a clear separation of the subjects in
two groups, whose relationship with the
subject characteristics is investigated.
|
|
F. Pierri, C. Piccardi, and S. Ceri, A multi-layer approach to disinformation detection in US and Italian news spreading on Twitter, EPJ Data Science, 9, 35, 2020. [doi] 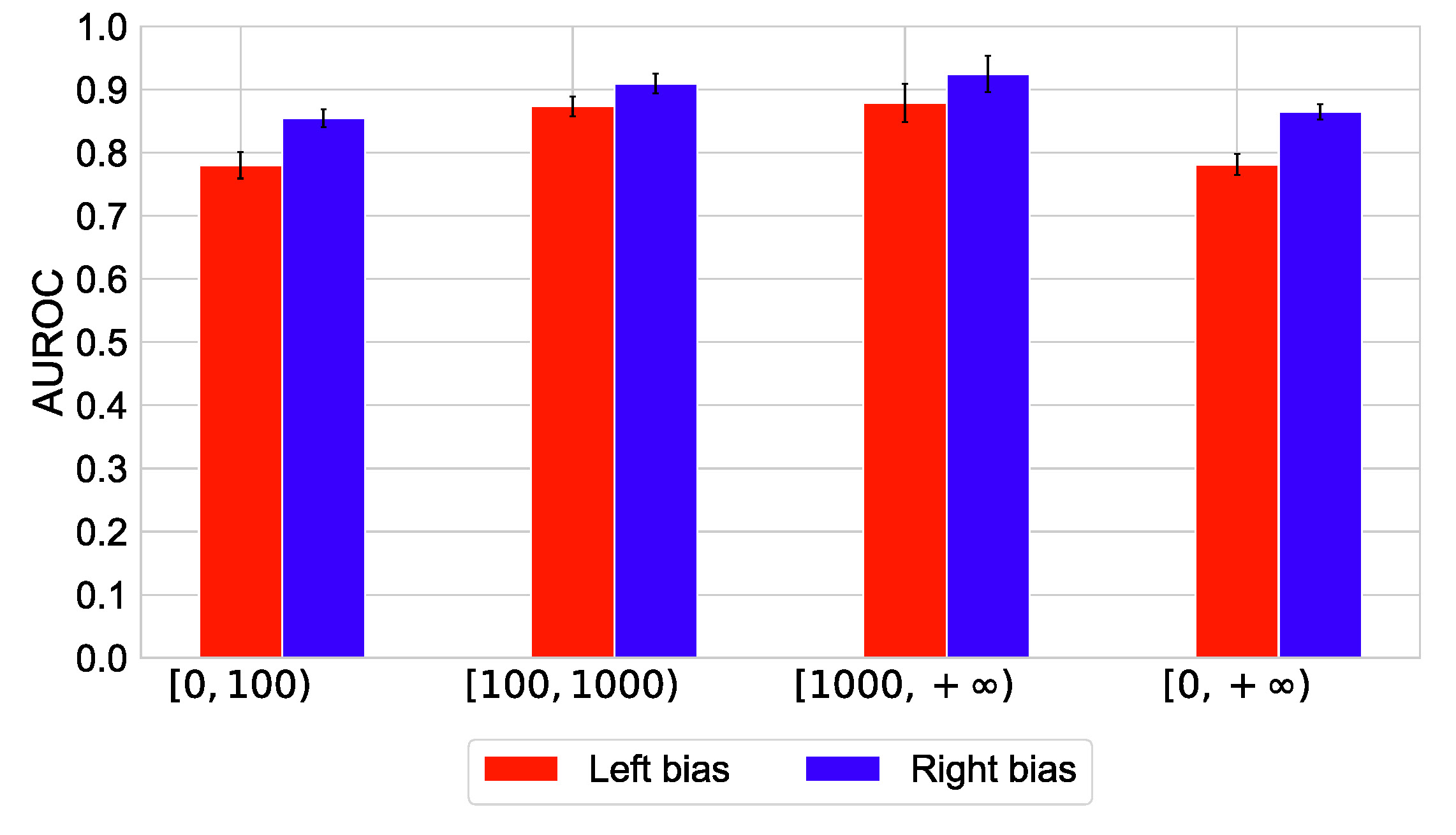 We tackle
the problem of classifying news articles
pertaining to disinformation vs
mainstream news by solely inspecting
their diffusion mechanisms on Twitter.
This approach is inherently simple
compared to existing text-based
approaches, as it allows to by-pass the
multiple levels of complexity which are
found in news content (e.g. grammar,
syntax, style). As we employ a
multi-layer representation of Twitter
diffusion networks where each layer
describes one single type of interaction
(tweet, retweet, mention, etc.), we
quantify the advantage of separating the
layers with respect to an aggregated
approach and assess the impact of each
layer on the classification.
Experimental results with two
large-scale datasets, corresponding to
diffusion cascades of news shared
respectively in the United States and
Italy, show that a simple Logistic
Regression model is able to classify
disinformation vs mainstream networks
with high accuracy (AUROC up to 94%). We
also highlight differences in the
sharing patterns of the two news domains
which appear to be common in the two
countries. We believe that our
network-based approach provides useful
insights which pave the way to the
future development of a system to detect
misleading and harmful information
spreading on social media. We tackle
the problem of classifying news articles
pertaining to disinformation vs
mainstream news by solely inspecting
their diffusion mechanisms on Twitter.
This approach is inherently simple
compared to existing text-based
approaches, as it allows to by-pass the
multiple levels of complexity which are
found in news content (e.g. grammar,
syntax, style). As we employ a
multi-layer representation of Twitter
diffusion networks where each layer
describes one single type of interaction
(tweet, retweet, mention, etc.), we
quantify the advantage of separating the
layers with respect to an aggregated
approach and assess the impact of each
layer on the classification.
Experimental results with two
large-scale datasets, corresponding to
diffusion cascades of news shared
respectively in the United States and
Italy, show that a simple Logistic
Regression model is able to classify
disinformation vs mainstream networks
with high accuracy (AUROC up to 94%). We
also highlight differences in the
sharing patterns of the two news domains
which appear to be common in the two
countries. We believe that our
network-based approach provides useful
insights which pave the way to the
future development of a system to detect
misleading and harmful information
spreading on social media.
|
|
F. Pierri, C. Piccardi, and S. Ceri, Topology comparison of Twitter diffusion networks effectively reveals misleading information, Scientific Reports, 10, 1372, 2020. [doi] 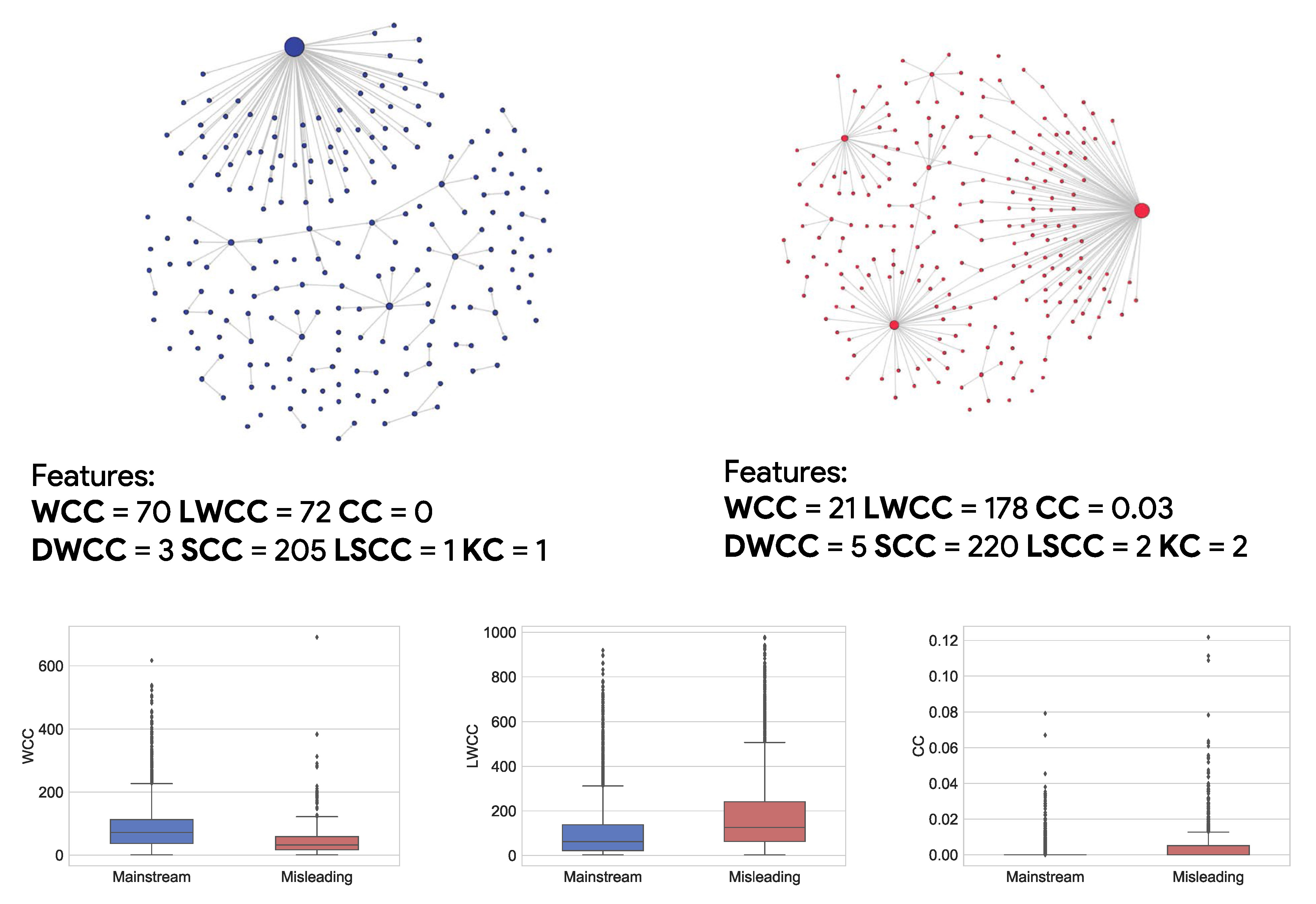 In recent
years, malicious information had an
explosive growth in social media, with
serious social and political backlashes.
Recent important studies, featuring
large-scale analyses, have produced
deeper knowledge about this phenomenon,
showing that misleading information
spreads faster, deeper and more broadly
than factual information on social
media, where echo chambers, algorithmic
and In recent
years, malicious information had an
explosive growth in social media, with
serious social and political backlashes.
Recent important studies, featuring
large-scale analyses, have produced
deeper knowledge about this phenomenon,
showing that misleading information
spreads faster, deeper and more broadly
than factual information on social
media, where echo chambers, algorithmic
andhuman biases play an important role in diffusion networks. Following these directions, we explore the possibility of classifying news articles circulating on social media based exclusively on a topological analysis of their diffusion networks. To this aim we collected a large dataset of diffusion networks on Twitter pertaining to news articles published on two distinct classes of sources, namely outlets that convey mainstream, reliable and objective information and those that fabricate and disseminate various kinds of misleading articles, including false news intended to harm, satire intended to make people laugh, click-bait news that may be entirely factual or rumors that are unproven. We carried out an extensive comparison of these networks using several alignment-free approaches including basic network properties, centrality measures distributions, and network distances. We accordingly evaluated to what extent these techniques allow to discriminate between the networks associated to the aforementioned news domains. Our results highlight that the communities of users spreading mainstream news, compared to those sharing misleading news, tend to shape diffusion networks with subtle yet systematic differences which might be effectively employed to identify misleading and harmful information. |
|
M. Tantardini, F. Ieva, L. Tajoli, and C. Piccardi, Comparing methods for comparing networks, Scientific Reports, 9, 17557, 2019. [doi] 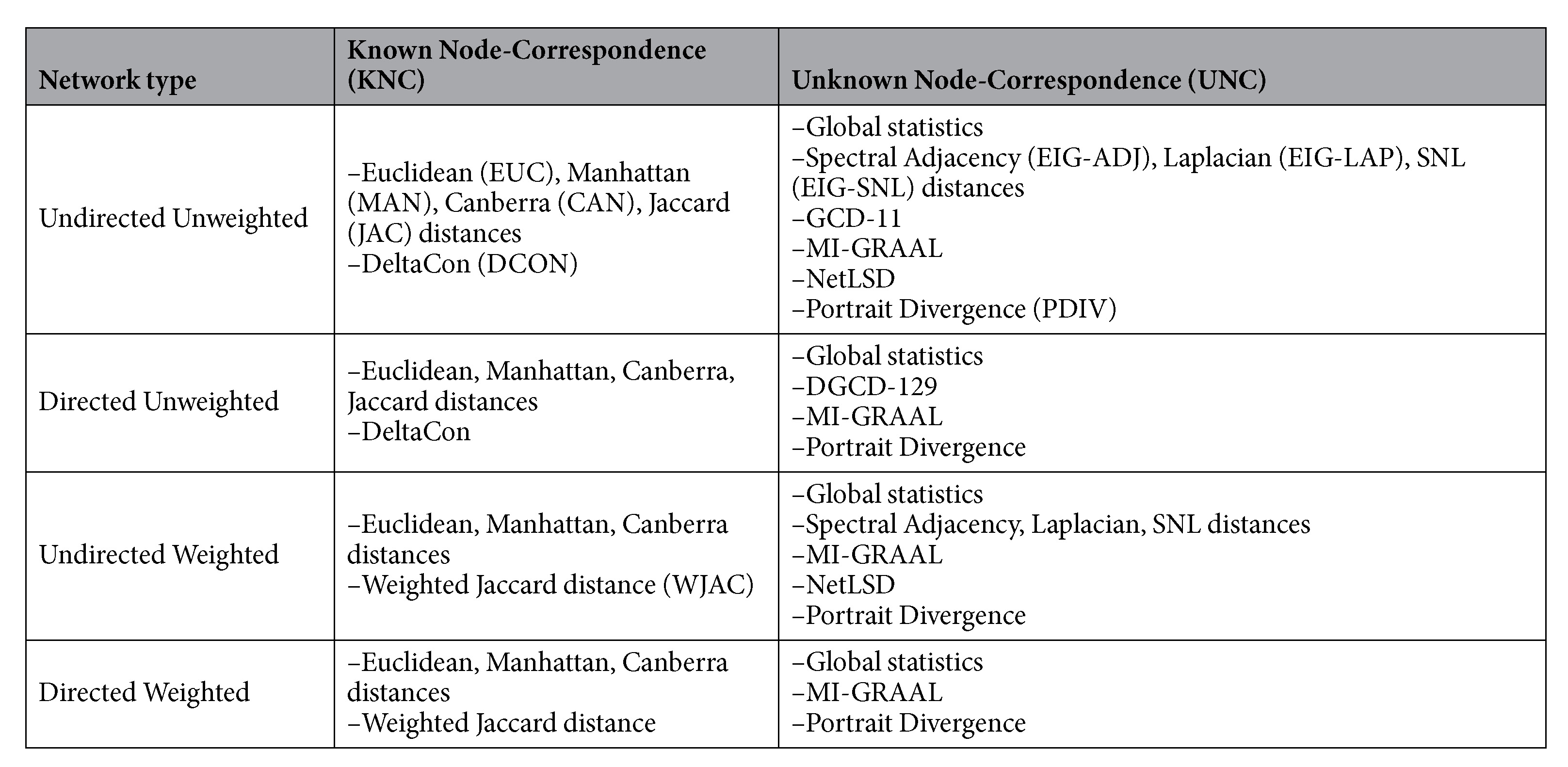 With
the impressive growth of available data
and the flexibility of network
modelling, the problem of devising
effective quantitative methods for the
comparison of networks arises. Plenty of
such methods have been designed to
accomplish this task: most of them deal
with undirected and unweighted networks
only, but a few are capable of handling
directed and/or weighted networks too,
thus properly exploiting richer
information. In this work, we contribute
to the effort of comparing the different
methods for comparing networks and
providing a guide for the selection of
an appropriate one. First, we review and
classify a collection of network
comparison methods, highlighting the
criteria they are based on and their
advantages and drawbacks. The set
includes methods requiring known node
correspondence, such as DeltaCon and Cut
Distance, as well as methods not
requiring a priori known
node-correspondence, such as
alignment-based, graphlet-based, and
spectral methods, and the recently
proposed Portrait Divergence and NetLSD.
We test the above methods on synthetic
networks and we assess their usability
and the meaningfulness of the results
they provide. Finally, we apply the
methods to two real-world datasets, the
European Air Transportation Network and
the FAO Trade Network, in order to
discuss the results that can be drawn
from this type of analysis. With
the impressive growth of available data
and the flexibility of network
modelling, the problem of devising
effective quantitative methods for the
comparison of networks arises. Plenty of
such methods have been designed to
accomplish this task: most of them deal
with undirected and unweighted networks
only, but a few are capable of handling
directed and/or weighted networks too,
thus properly exploiting richer
information. In this work, we contribute
to the effort of comparing the different
methods for comparing networks and
providing a guide for the selection of
an appropriate one. First, we review and
classify a collection of network
comparison methods, highlighting the
criteria they are based on and their
advantages and drawbacks. The set
includes methods requiring known node
correspondence, such as DeltaCon and Cut
Distance, as well as methods not
requiring a priori known
node-correspondence, such as
alignment-based, graphlet-based, and
spectral methods, and the recently
proposed Portrait Divergence and NetLSD.
We test the above methods on synthetic
networks and we assess their usability
and the meaningfulness of the results
they provide. Finally, we apply the
methods to two real-world datasets, the
European Air Transportation Network and
the FAO Trade Network, in order to
discuss the results that can be drawn
from this type of analysis. |
|
A. Mechiche-Alami, C. Piccardi, K.A. Nicholas, J.W. Seaquist, Transnational land acquisitions beyond the food and financial crises, Environmental Research Letters, 14, 084021, 2019. [doi] 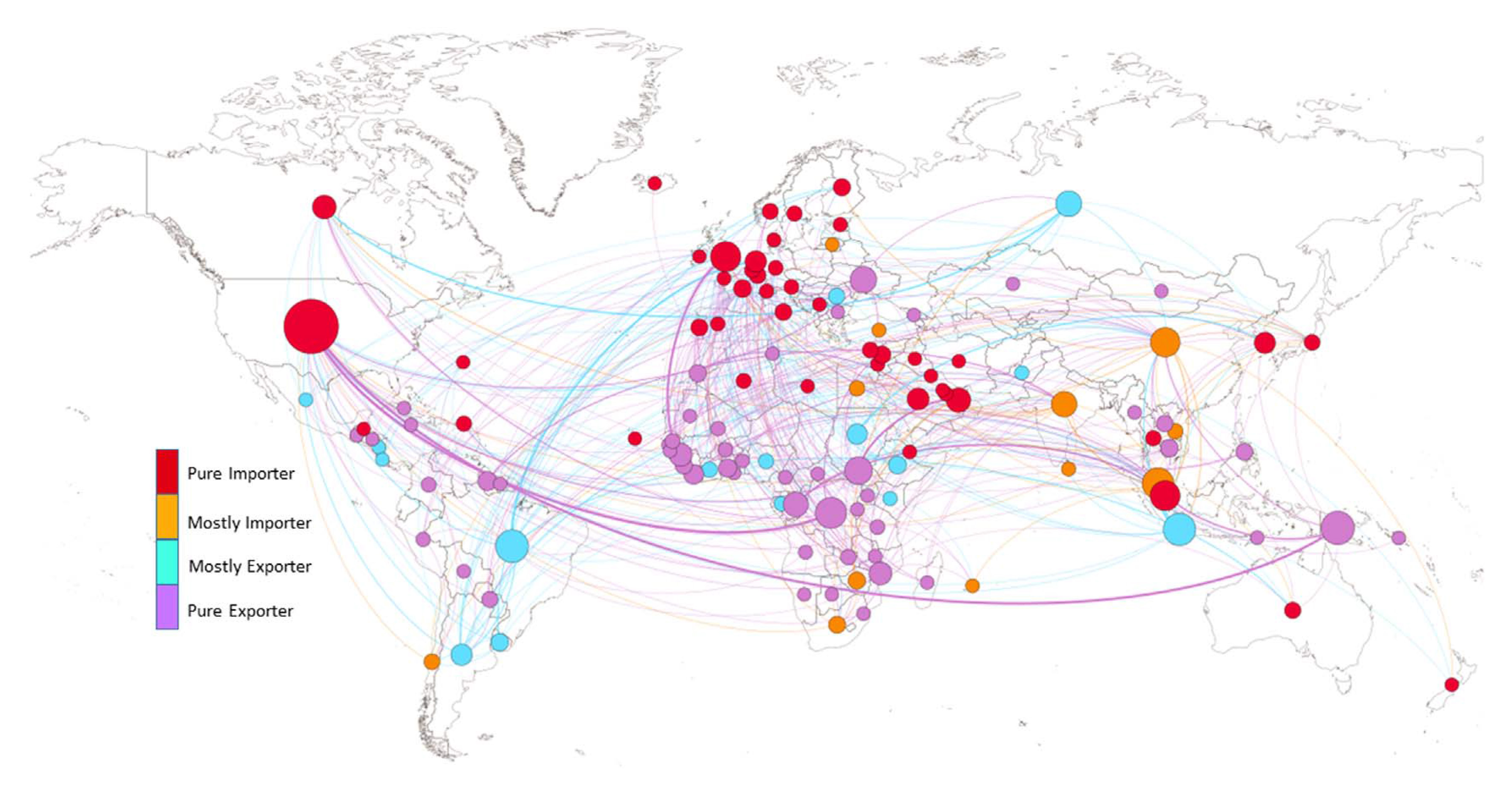 Large-scale
land acquisitions (LSLA) in
resource-rich countries came to global
attention after the food and financial
crises of 2008. Previous research has
assessed the magnitude of these land
investments in terms of land areas
acquired. In this study,we analyze the
trends in the evolution of LSLA by
framing the latter as virtual land trade
network with land transactions occurring
between 2000 and 2015, in order to shed
light on the development and evolution
of this system. Based on an index we
introduce to represent both the number
of countries and size of deals,we
discover three main phases of trade
activity: a steady increase from2000
until 2007 (Phase 1) followed by a peak
coinciding with the food and financial
crises between 2008 and 2010 (Phase 2)
and concluded by a decline from 2011 to
2015 (Phase 3).We identify 73 countries
that remained active in land trading
during all three phases and forma core
of land traders much larger than
previously thought. Using network
analysis methods, we group countries
with similar trade patterns into
categories of competitive, preferential,
diversified, and occasional importers or
exporters. Finally, in exploring the
changes in investors and their interests
in land throughout the phases, we
attribute the evolution of LSLA to the
different stages in the globalization
and financialization of different
industries. By showing that land
investments seem fully integrated as
investment strategies across industries
we argue for the urgency of better
regulation of LSLA so that they also
benefit local populations without
damaging the environment regardless of
their primary purpose. Large-scale
land acquisitions (LSLA) in
resource-rich countries came to global
attention after the food and financial
crises of 2008. Previous research has
assessed the magnitude of these land
investments in terms of land areas
acquired. In this study,we analyze the
trends in the evolution of LSLA by
framing the latter as virtual land trade
network with land transactions occurring
between 2000 and 2015, in order to shed
light on the development and evolution
of this system. Based on an index we
introduce to represent both the number
of countries and size of deals,we
discover three main phases of trade
activity: a steady increase from2000
until 2007 (Phase 1) followed by a peak
coinciding with the food and financial
crises between 2008 and 2010 (Phase 2)
and concluded by a decline from 2011 to
2015 (Phase 3).We identify 73 countries
that remained active in land trading
during all three phases and forma core
of land traders much larger than
previously thought. Using network
analysis methods, we group countries
with similar trade patterns into
categories of competitive, preferential,
diversified, and occasional importers or
exporters. Finally, in exploring the
changes in investors and their interests
in land throughout the phases, we
attribute the evolution of LSLA to the
different stages in the globalization
and financialization of different
industries. By showing that land
investments seem fully integrated as
investment strategies across industries
we argue for the urgency of better
regulation of LSLA so that they also
benefit local populations without
damaging the environment regardless of
their primary purpose.
|
|
F. Riva, E. Colombo, C. Piccardi, Towards modelling diffusion mechanisms for sustainable off-grid electricity planning, Energy for Sustainable Development, 52, 11-25, 2019. [doi] 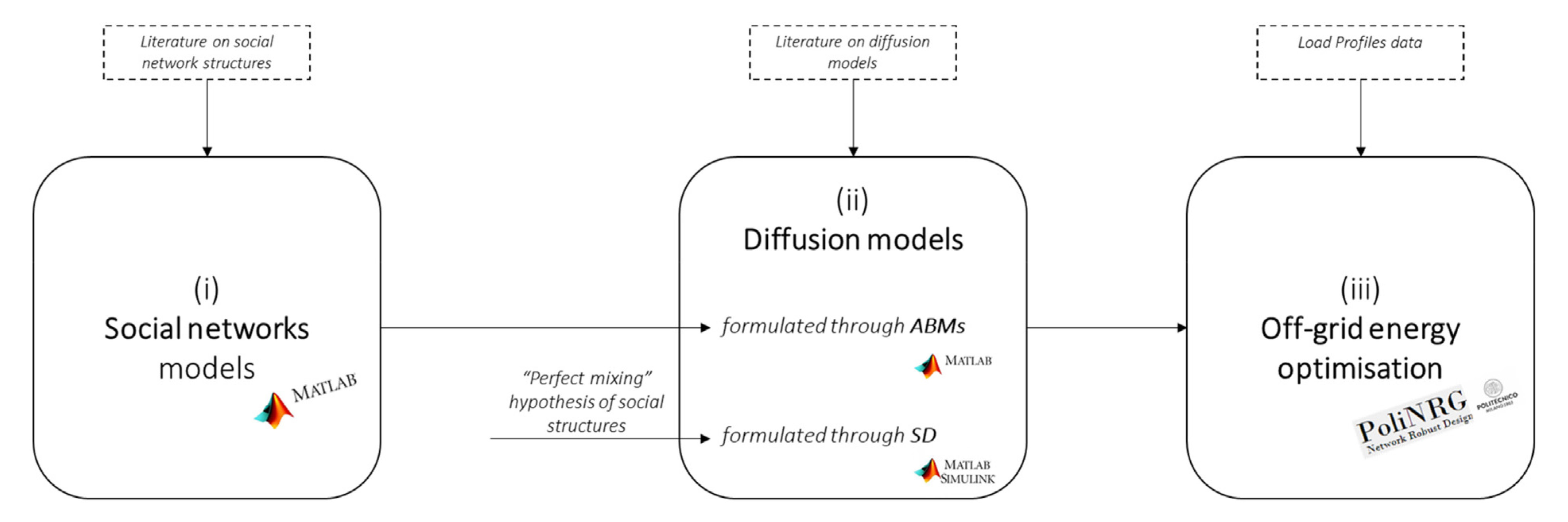 The
electrification-based literature reports
a limited knowledge about the mechanisms
of evolution of electricity demand in
off-grid settings, especially in remote
contexts of developing countries, due to
the lack of robust and appropriate
modelling frameworks. Such lack of
understanding and modelling endeavour
contributes to an inefficient allocation
of resources for electrification
projects and inappropriate off-grid
sizing processes. As a first step
towards the development of a more
appropriate electricity demand model, we
present a comparative study of two
approaches for modelling different
diffusion mechanisms of electricity
connections: system-dynamics and
agent-based models. The latter includes
the modelling of social network
archetypes in the simulation of
diffusion processes. We model different
scenarios of diffusion and we use them
for evaluating the impact on the sizing
process of an off-grid hydroelectric
system. The results suggest that the
structure of the social network can
represent a crucial parameter that can
impact on timing needed to complete the
diffusion of electricity access - from
few months to even >10 years. This
affects the sizing process and the
long-term sustainability of the power
system, leading to variation of the
hydroelectric capacity and the battery
size up to around 55% and 100%,
respectively. Our results indicate that
the agent-based approach allows a more
diversified representation of diffusion
processes, but the limitations and
scarcity of data can be an obstacle to
their prompt application for energy
application in unelectrified areas. On
the contrary, system-dynamics can
represent a more appropriate method
since it requires less quantitative data
and it provides a more structural and
holistic modelling framework for
conceptualising and formulating in a the
determinants and complexities affecting
the evolution of electricity demand in
unelectrified areas. The
electrification-based literature reports
a limited knowledge about the mechanisms
of evolution of electricity demand in
off-grid settings, especially in remote
contexts of developing countries, due to
the lack of robust and appropriate
modelling frameworks. Such lack of
understanding and modelling endeavour
contributes to an inefficient allocation
of resources for electrification
projects and inappropriate off-grid
sizing processes. As a first step
towards the development of a more
appropriate electricity demand model, we
present a comparative study of two
approaches for modelling different
diffusion mechanisms of electricity
connections: system-dynamics and
agent-based models. The latter includes
the modelling of social network
archetypes in the simulation of
diffusion processes. We model different
scenarios of diffusion and we use them
for evaluating the impact on the sizing
process of an off-grid hydroelectric
system. The results suggest that the
structure of the social network can
represent a crucial parameter that can
impact on timing needed to complete the
diffusion of electricity access - from
few months to even >10 years. This
affects the sizing process and the
long-term sustainability of the power
system, leading to variation of the
hydroelectric capacity and the battery
size up to around 55% and 100%,
respectively. Our results indicate that
the agent-based approach allows a more
diversified representation of diffusion
processes, but the limitations and
scarcity of data can be an obstacle to
their prompt application for energy
application in unelectrified areas. On
the contrary, system-dynamics can
represent a more appropriate method
since it requires less quantitative data
and it provides a more structural and
holistic modelling framework for
conceptualising and formulating in a the
determinants and complexities affecting
the evolution of electricity demand in
unelectrified areas.
|
|
F. Dercole, F. Della Rossa, C. Piccardi, Direct reciprocity and model-predictive rationality explain network reciprocity over social ties, Scientific Reports, 9, 5367, 2019. [doi]  Since
M. A. Nowak & R. May's (1992)
influential paper, limiting each agent's
interactions to a few neighbors in a
network of contacts has been proposed as
the simplest mechanism to support the
evolution of cooperation in biological
and socio-economic systems. The network
allows cooperative agents to self-assort
into clusters, within which they
reciprocate cooperation. This (induced)
network reciprocity has been observed in
several theoreticalmodels and shown to
predict the fixation of cooperation
under a simple rule: the benefit
produced by an act of cooperation must
outweigh the cost of cooperating with
all neighbors. However, the experimental
evidence among humans is controversial:
though the rule seems to be confirmed,
the underlying modeling assumptions are
not. Specifically, models assume that
agents update their strategies by
imitating better performing neighbors,
even though imitation lacks rationality
when interactions are far from
all-to-all. Indeed, imitation did not
emerge in experiments. What did emerge
is that humans are conditioned by their
own mood and that, when in a cooperative
mood, they reciprocate cooperation. To
help resolve the controversy, we design
a model in which we rationally confront
the two main behaviors emerging from
experiments - reciprocal cooperation and
unconditional defection - in a networked
prisoner's dilemma. Rationality is
introduced by means of a predictive rule
for strategy update and is bounded by
the assumed model society. We show that
both reciprocity and a multi-step
predictive horizon are necessary to
stabilize cooperation, and sufficient
for its fixation, provided the game
benefit-to-cost ratio is larger than a
measure of network connectivity. We
hence rediscover the rule of network
reciprocity, underpinned however by a
different evolutionary mechanism. Since
M. A. Nowak & R. May's (1992)
influential paper, limiting each agent's
interactions to a few neighbors in a
network of contacts has been proposed as
the simplest mechanism to support the
evolution of cooperation in biological
and socio-economic systems. The network
allows cooperative agents to self-assort
into clusters, within which they
reciprocate cooperation. This (induced)
network reciprocity has been observed in
several theoreticalmodels and shown to
predict the fixation of cooperation
under a simple rule: the benefit
produced by an act of cooperation must
outweigh the cost of cooperating with
all neighbors. However, the experimental
evidence among humans is controversial:
though the rule seems to be confirmed,
the underlying modeling assumptions are
not. Specifically, models assume that
agents update their strategies by
imitating better performing neighbors,
even though imitation lacks rationality
when interactions are far from
all-to-all. Indeed, imitation did not
emerge in experiments. What did emerge
is that humans are conditioned by their
own mood and that, when in a cooperative
mood, they reciprocate cooperation. To
help resolve the controversy, we design
a model in which we rationally confront
the two main behaviors emerging from
experiments - reciprocal cooperation and
unconditional defection - in a networked
prisoner's dilemma. Rationality is
introduced by means of a predictive rule
for strategy update and is bounded by
the assumed model society. We show that
both reciprocity and a multi-step
predictive horizon are necessary to
stabilize cooperation, and sufficient
for its fixation, provided the game
benefit-to-cost ratio is larger than a
measure of network connectivity. We
hence rediscover the rule of network
reciprocity, underpinned however by a
different evolutionary mechanism.
|
|
C. Piccardi and L. Tajoli, Complexity, centralization, and fragility in economic networks, PLoS One, 13(11), e0208265, 2018. [doi] 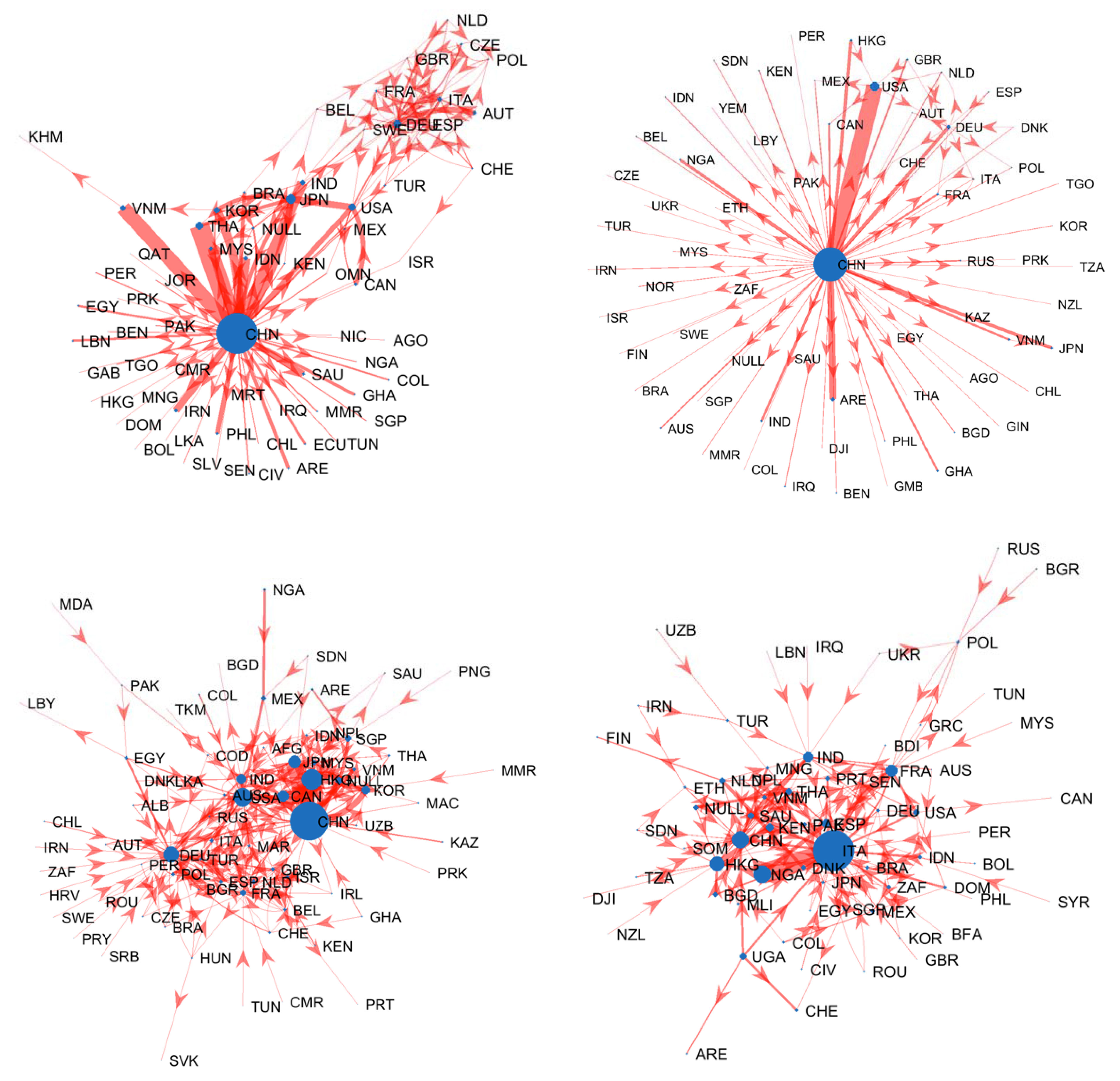 Trade networks, across which
countries distribute their products,
are crucial components of the
globalized world economy. Their
structure affects the mechanism of
propagation of shocks from country to
country, as observed in a very sharp
way in the past decade, characterized
by economic uncertainty in many parts
of the world. Such trade structures
are strongly heterogeneous across
products, given the different features
of the countries which buy and sell
goods. By using a diversified pool of
indicators from network science and
product complexity theory, we
quantitatively demonstrate that,
overall, products with higher
complexity - i.e., with larger
technological content and/or number of
components - are traded through more
centralized networks - i.e., with a
smaller number of countries
concentrating most of the export flow.
Since centralized networks are known
to be more vulnerable, we argue that
the current composition of production
and trading is associated to high
fragility at the level of the most
complex - thus strategic - products. Trade networks, across which
countries distribute their products,
are crucial components of the
globalized world economy. Their
structure affects the mechanism of
propagation of shocks from country to
country, as observed in a very sharp
way in the past decade, characterized
by economic uncertainty in many parts
of the world. Such trade structures
are strongly heterogeneous across
products, given the different features
of the countries which buy and sell
goods. By using a diversified pool of
indicators from network science and
product complexity theory, we
quantitatively demonstrate that,
overall, products with higher
complexity - i.e., with larger
technological content and/or number of
components - are traded through more
centralized networks - i.e., with a
smaller number of countries
concentrating most of the export flow.
Since centralized networks are known
to be more vulnerable, we argue that
the current composition of production
and trading is associated to high
fragility at the level of the most
complex - thus strategic - products. |
|
M. Bastos, C. Piccardi, M. Levy, N. McRoberts, and M. Lubell, Core-periphery or decentralized? Topological shifts of specialized information on Twitter, Social Networks, 52, 282-293, 2018. [doi]  In
this paper we investigate shifts in
Twitter network topology resulting from
the type of information being shared. We
identified communities matching areas of
agricultural expertise and measured the
core-periphery centralization of network
formations resulting from users sharing
generic versus specialized information.
We found that centralization increases
when specialized information is shared
and that the network adopts
decentralized formations as
conversations become more generic. The
results are consistent with classical
diffusion models positing that
specialized information comes with
greater centralization, but they also
show that users favor decentralized
formations, which can foster community
cohesion, when spreading specialized
information is secondary. In
this paper we investigate shifts in
Twitter network topology resulting from
the type of information being shared. We
identified communities matching areas of
agricultural expertise and measured the
core-periphery centralization of network
formations resulting from users sharing
generic versus specialized information.
We found that centralization increases
when specialized information is shared
and that the network adopts
decentralized formations as
conversations become more generic. The
results are consistent with classical
diffusion models positing that
specialized information comes with
greater centralization, but they also
show that users favor decentralized
formations, which can foster community
cohesion, when spreading specialized
information is secondary. |
|
C. Piccardi, M. Riccaboni, L. Tajoli, and Zhen Zhu, Random walks on the world input-output network, Journal of Complex Networks, 6, 187-205, 2018. [doi] 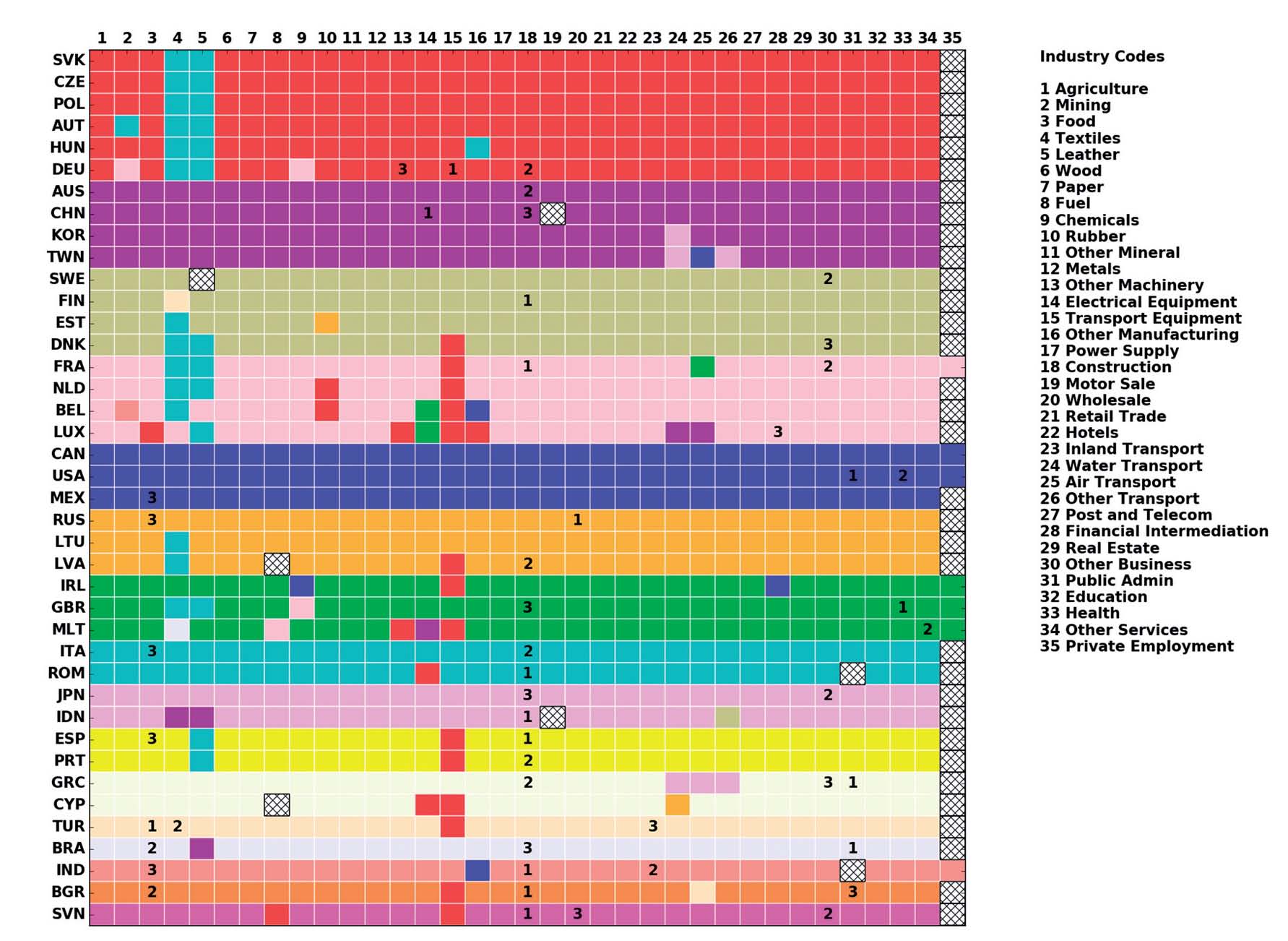 Modern
production is increasingly fragmented
across countries.To disentangle the
world production system at sector level,
we use the World Input-Output Database
to construct the World Input-Output
Network (WION) where the nodes are the
individual sectors in different
countries and the edges are the
transactions between them. In order to
explore the features and dynamics of the
WION, in this article we detect the
communities in the WION and evaluate
their significance using a random walk
Markov chain approach. Our results
contribute to the recent stream of
literature analysing the role of global
value chains in economic integration
across countries, by showing global
value chains as endogenously emerging
communities in the world production
system, and discussing how different
perspectives produce different results
in terms of the pattern of integration. Modern
production is increasingly fragmented
across countries.To disentangle the
world production system at sector level,
we use the World Input-Output Database
to construct the World Input-Output
Network (WION) where the nodes are the
individual sectors in different
countries and the edges are the
transactions between them. In order to
explore the features and dynamics of the
WION, in this article we detect the
communities in the WION and evaluate
their significance using a random walk
Markov chain approach. Our results
contribute to the recent stream of
literature analysing the role of global
value chains in economic integration
across countries, by showing global
value chains as endogenously emerging
communities in the world production
system, and discussing how different
perspectives produce different results
in terms of the pattern of integration.
|
|
F. Calderoni, D. Brunetto, and C. Piccardi, Communities in criminal networks: A case study, Social Networks, 48, 116-125, 2017. [doi] 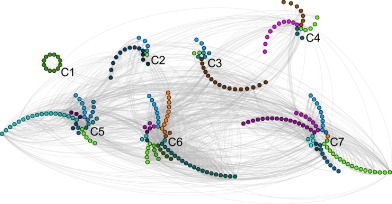 Criminal
organizations tend to be clustered to
reduce risks of detection and
information leaks. Yet, the literature
exploring the relevance of subgroups for
their internal structure is so far very
limited. The paper applies methods of
community analysis to explore the
structure of a criminal network
representing the individuals'
co-participation in meetings. It draws
from a case study on a large law
enforcement operation (``Operazione
Infinito'') tackling the 'Ndrangheta, a
mafia organization from Calabria, a
southern Italian region. The results
show that the network is indeed
clustered and that communities are
associated, in a non trivial way, with
the internal organization of the
'Ndrangheta into different ``locali''
(similar to mafia families).
Furthermore, the results of community
analysis can improve the prediction of
the ``locale'' membership of the
criminals (up to two thirds of any
random sample of nodes) and the
leadership roles (above 90% precision in
classifying nodes as either bosses or
non-bosses). The implications of these
findings on the interpretation of the
structure and functioning of the
criminal network are discussed. Criminal
organizations tend to be clustered to
reduce risks of detection and
information leaks. Yet, the literature
exploring the relevance of subgroups for
their internal structure is so far very
limited. The paper applies methods of
community analysis to explore the
structure of a criminal network
representing the individuals'
co-participation in meetings. It draws
from a case study on a large law
enforcement operation (``Operazione
Infinito'') tackling the 'Ndrangheta, a
mafia organization from Calabria, a
southern Italian region. The results
show that the network is indeed
clustered and that communities are
associated, in a non trivial way, with
the internal organization of the
'Ndrangheta into different ``locali''
(similar to mafia families).
Furthermore, the results of community
analysis can improve the prediction of
the ``locale'' membership of the
criminals (up to two thirds of any
random sample of nodes) and the
leadership roles (above 90% precision in
classifying nodes as either bosses or
non-bosses). The implications of these
findings on the interpretation of the
structure and functioning of the
criminal network are discussed. |
|
G. Berlusconi, F. Calderoni, N. Parolini, M. Verani, and C. Piccardi, Link prediction in criminal networks: A tool for criminal intelligence analysis, PLoS ONE, 11(4): e0154244, 2016. [doi] 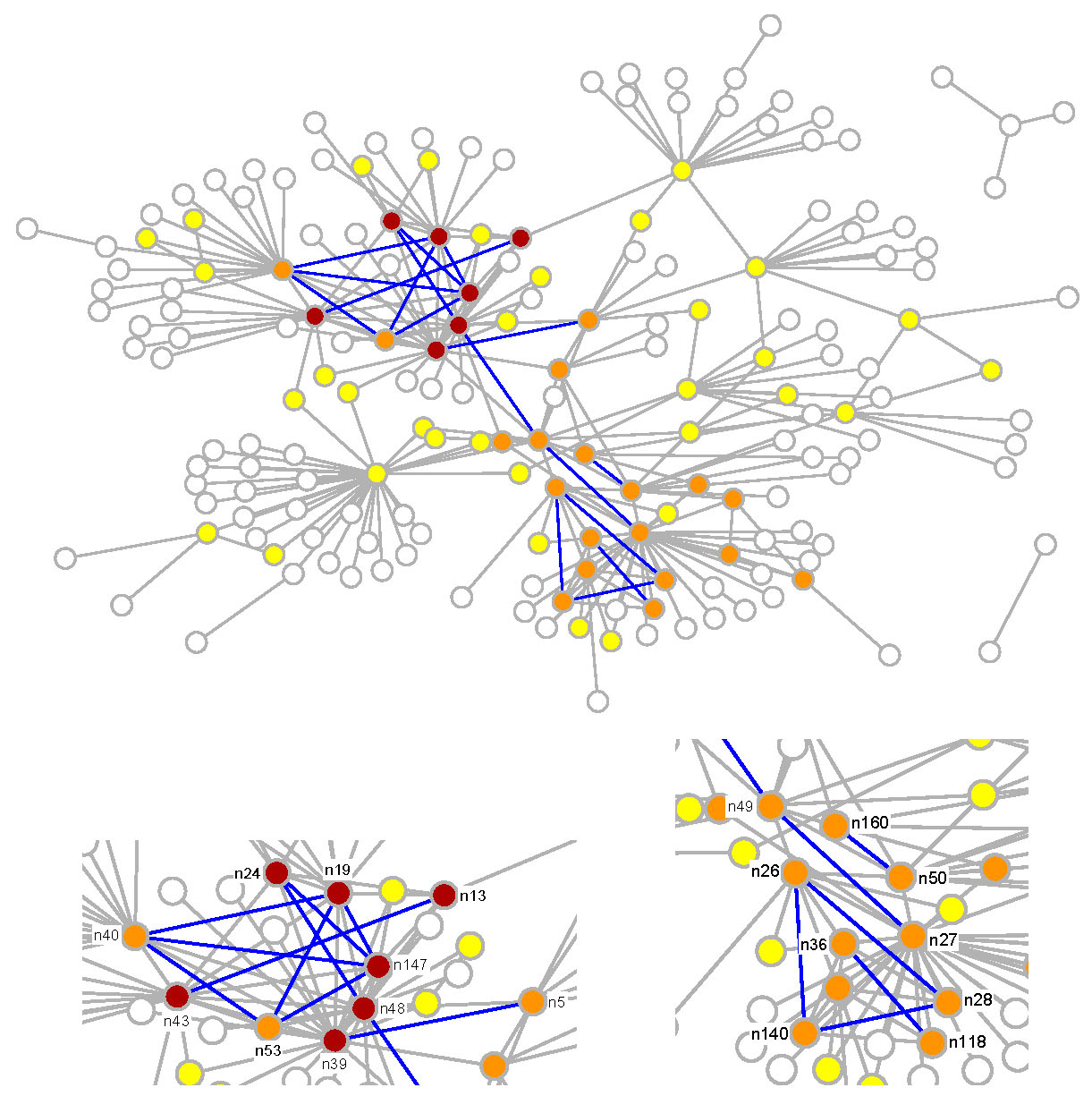 The
problem of link prediction has recently
received increasing attention from
scholars in network science. In social
network analysis, one of its aims is to
recover missing links, namely connections
among actors which are likely to exist but
have not been reported because data are
incomplete or subject to various types of
uncertainty. In the field of criminal
investigations, problems of incomplete
information are encountered almost by
definition, given the obvious
anti-detection strategies set up by
criminals and the limited investigative
resources. In this paper, we work on a
specific dataset obtained from a real
investigation, and we propose a strategy
to identify missing links in a criminal
network on the basis of the topological
analysis of the links classified as
marginal, i.e. removed during the
investigation procedure. The main
assumption is that missing links should
have opposite features with respect to
marginal ones. Measures of node similarity
turn out to provide the best
characterization in this sense. The
inspection of the judicial source
documents confirms that the predicted
links, in most instances, do relate actors
with large likelihood of co-participation
in illicit activities. The
problem of link prediction has recently
received increasing attention from
scholars in network science. In social
network analysis, one of its aims is to
recover missing links, namely connections
among actors which are likely to exist but
have not been reported because data are
incomplete or subject to various types of
uncertainty. In the field of criminal
investigations, problems of incomplete
information are encountered almost by
definition, given the obvious
anti-detection strategies set up by
criminals and the limited investigative
resources. In this paper, we work on a
specific dataset obtained from a real
investigation, and we propose a strategy
to identify missing links in a criminal
network on the basis of the topological
analysis of the links classified as
marginal, i.e. removed during the
investigation procedure. The main
assumption is that missing links should
have opposite features with respect to
marginal ones. Measures of node similarity
turn out to provide the best
characterization in this sense. The
inspection of the judicial source
documents confirms that the predicted
links, in most instances, do relate actors
with large likelihood of co-participation
in illicit activities. |
|
I. Cingolani, C. Piccardi, and L. Tajoli, Discovering preferential patterns in sectoral trade networks, PLoS ONE, 10(10), e0140951, 2015. [doi] 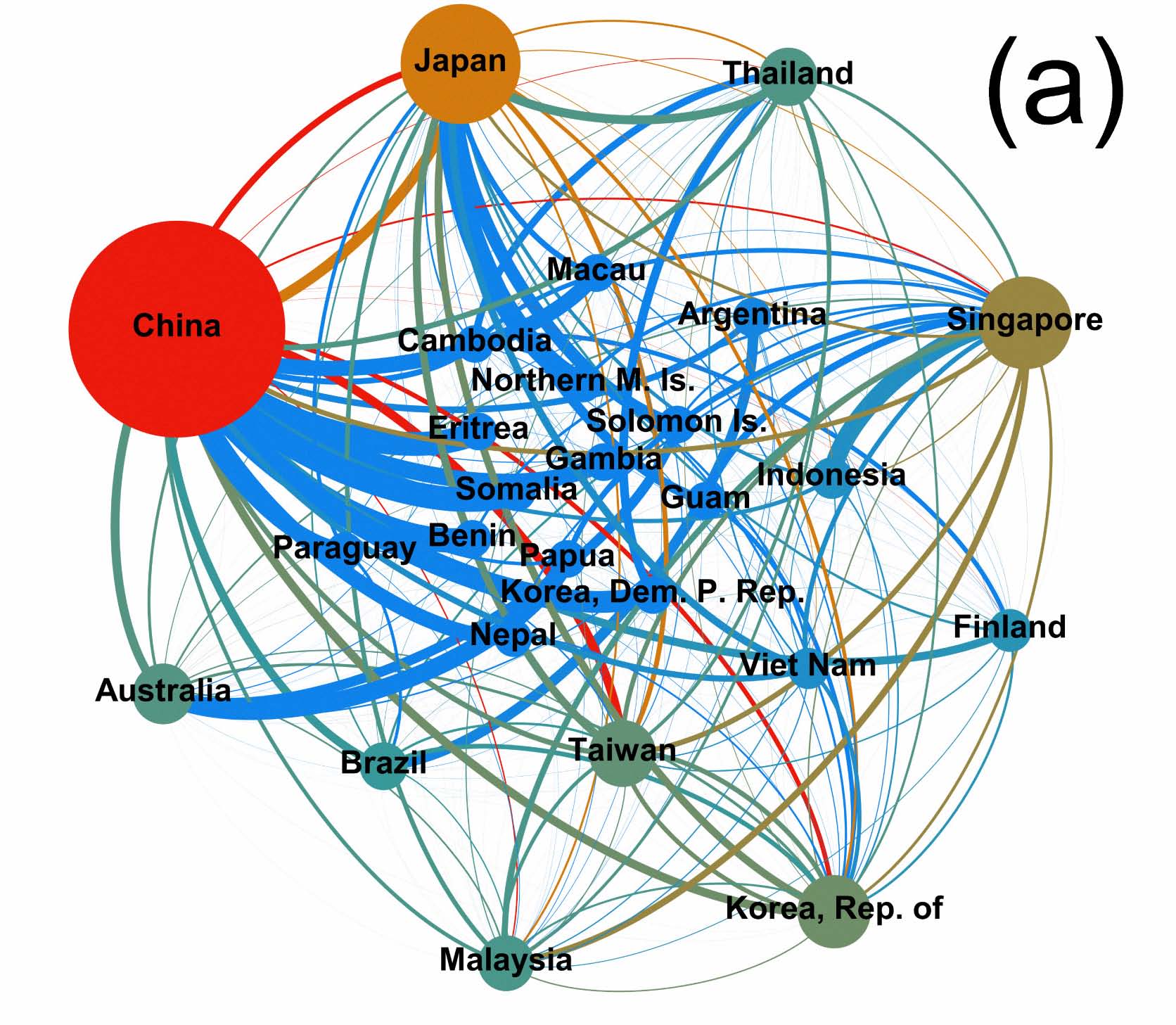 We
analyze the patterns of import/export
bilateral relations, with the aim of
assessing the relevance and shape of
"preferentiality" in countries' trade
decisions. Preferentiality here is defined
as the tendency to concentrate trade on
one or few partners. With this purpose, we
adopt a systemic approach through the use
of the tools of complex network analysis.
In particular, we apply a pattern
detection We
analyze the patterns of import/export
bilateral relations, with the aim of
assessing the relevance and shape of
"preferentiality" in countries' trade
decisions. Preferentiality here is defined
as the tendency to concentrate trade on
one or few partners. With this purpose, we
adopt a systemic approach through the use
of the tools of complex network analysis.
In particular, we apply a pattern
detectionapproach based on community and pseudocommunity analysis, in order to highlight the groups of countries within which most of members' trade occur. The method is applied to two intra-industry trade networks consisting of 221 countries, relative to the low-tech "Textiles and Textile Articles" and the high-tech "Electronics" sectors for the year 2006, to look at the structure of world trade before the start of the international financial crisis. It turns out that the two networks display some similarities and some differences in preferential trade patterns: they both include few significant communities that define narrow sets of countries trading with each other as preferential destinations markets or supply sources, and they are characterized by the presence of similar hierarchical structures, led by the largest economies. But there are also distinctive features due to the characteristics of the industries examined, in which the organization of production and the destination markets are different. Overall, the extent of preferentiality and partner selection at the sector level confirm the relevance of international trade costs still today, inducing countries to seek the highest efficiency in their trade patterns. |
|
C. Piccardi, A. Colombo, and R. Casagrandi, Connectivity interplays with age in shaping contagion over networks with vital dynamics, Physical Review E, 91(2), 022809, 2015. [doi] 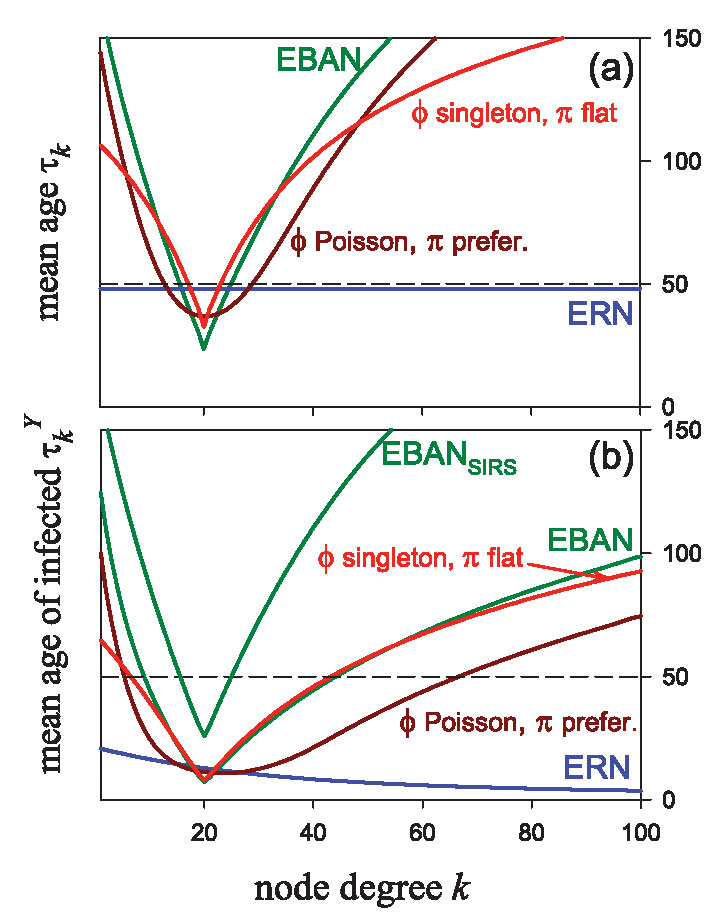 The
effects of network topology on the
emergence and persistence of infectious
diseases have been broadly explored in
recent years. However, the influence of
the vital dynamics of the hosts (i.e.,
birth-death processes) on the network
structure, and their effects on the
pattern of epidemics, have received less
attention in the scientific community.
Here, we study
Susceptible-Infected-Recovered(-Susceptible)
[SIR(S)] contact processes in standard
networks (of Erdos-Renyi and
Barabasi-Albert type) that are subject to
host demography. Accounting for the vital
dynamics of hosts is far from trivial, and
it causes the scale-free networks to lose
their characteristic fat-tailed degree
distribution.We introduce a broad class of
models that integrate the birth and death
of individuals (nodes) with the simplest
mechanisms of infection and recovery, thus
generating age-degree structured networks
of hosts that interact in a complex
manner. In our models, the epidemiological
state of each individualmay depend both on
the number of contacts (which changes
through time because of the birth-death
process) and on its age, paving the way
for a possible age-dependent description
of contagion and recovery processes.We
study how the proportion of infected
individuals scales with the number of
contacts among them. Rather unexpectedly,
we discover that the result of highly
connected individuals at the highest risk
of infection is not as general as commonly
believed. In infections that confer
permanent immunity to individuals of vital
populations (SIR processes), the nodes
that are most likely to be infected are
those with intermediate degrees. Our
age-degree structured models allow such
findings to be deeply analyzed and
interpreted, and they may aid in the
development of effective prevention
policies. The
effects of network topology on the
emergence and persistence of infectious
diseases have been broadly explored in
recent years. However, the influence of
the vital dynamics of the hosts (i.e.,
birth-death processes) on the network
structure, and their effects on the
pattern of epidemics, have received less
attention in the scientific community.
Here, we study
Susceptible-Infected-Recovered(-Susceptible)
[SIR(S)] contact processes in standard
networks (of Erdos-Renyi and
Barabasi-Albert type) that are subject to
host demography. Accounting for the vital
dynamics of hosts is far from trivial, and
it causes the scale-free networks to lose
their characteristic fat-tailed degree
distribution.We introduce a broad class of
models that integrate the birth and death
of individuals (nodes) with the simplest
mechanisms of infection and recovery, thus
generating age-degree structured networks
of hosts that interact in a complex
manner. In our models, the epidemiological
state of each individualmay depend both on
the number of contacts (which changes
through time because of the birth-death
process) and on its age, paving the way
for a possible age-dependent description
of contagion and recovery processes.We
study how the proportion of infected
individuals scales with the number of
contacts among them. Rather unexpectedly,
we discover that the result of highly
connected individuals at the highest risk
of infection is not as general as commonly
believed. In infections that confer
permanent immunity to individuals of vital
populations (SIR processes), the nodes
that are most likely to be infected are
those with intermediate degrees. Our
age-degree structured models allow such
findings to be deeply analyzed and
interpreted, and they may aid in the
development of effective prevention
policies. |
|
F. Della Rossa, M. Gobbi, G. Mastinu, C. Piccardi, and G. Previati, Bifurcation analysis of a car and driver model, Vehicle System Dynamics, 52, 142-156, 2014. [doi] 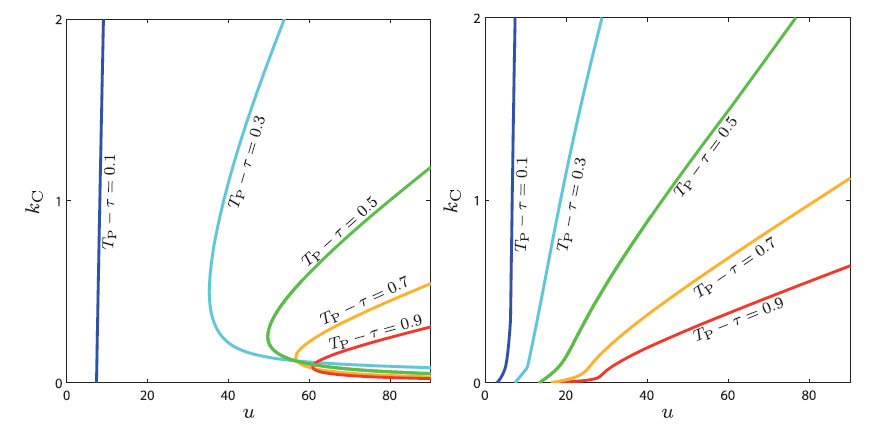
The bifurcation analysis
of a simple mathematical model describing
a road vehicle with a driver is presented.
The mechanical model of the car has two
degrees of freedom and the related
equations of motion contain the nonlinear
tyre characteristics. The driver is
described by a well-known model proposed
in the literature. The road vehicle model
has been validated in a case study.
Bifurcation analysis is adopted as the
proper procedure for analysing both
steady-state cornering and straight ahead
motion at different speeds. The importance
of properly computing steady-state
equilibria is highlighted. The effect of a
skilled driver is to broaden the basin of
attraction of stable equilibria and, in
some cases, to stabilise originally
unstable behaviours.Asubcritical Hopf
bifurcation is normally found which limits
the forward speed of either understeering
or oversteering vehicles. A
three-parameter bifurcation analysis is
performed to understand the influence on
stability of driver gain, of driver
prediction time, of vehicle speed. It
turns out, as expected from practice, that
an oversteering vehicle is more
challenging to be controlled than an
understeering one. The paper proposes an
insight into vehicle-driver interaction.
The stabilising or de-stabilising effect
of the driver is ultimately explained
referring to the existence of a Hopf
bifurcation.
|
|
P. Landi and C. Piccardi, Community analysis in directed networks: In-, out-, and pseudo-communities, Physical Review E, 89(1), 012814, 2014. [doi] 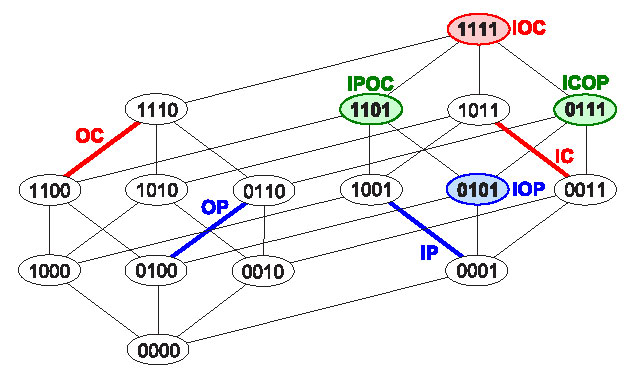 When
analyzing important classes of complex
interconnected systems, link directionality
can hardly be When
analyzing important classes of complex
interconnected systems, link directionality
can hardly beneglected if a precise and effective picture of the structure and function of the system is needed. If community analysis is performed, the notion of "community" itself is called into question, since the property of having a comparatively looser external connectivity could refer to the inbound or outbound links only or to both categories. In this paper, we introduce the notions of in-, out-, and in-/out-community in order to correctly classify the directedness of the interaction of a subnetwork with the rest of the system. Furthermore, we extend the scope of community analysis by introducing the notions of in-, out-, and in-/out-pseudocommunity. They are subnetworks having strong internal connectivity but also important interactions with the rest of the system, the latter taking place by means of a minority of its nodes only. The various types of (pseudo-)communities are qualified and distinguished by a suitable set of indicators and, on a given network, they can be discovered by using a "local" searching algorithm. The application to a broad set of benchmark networks and real-world examples proves that the proposed approach is able to effectively disclose the different types of structures above defined and to usefully classify the directionality of their interactions with the rest of the system. Matlab code and data used in the paper are available here. |
|
F. Della Rossa, F. Dercole, and C. Piccardi, Profiling core-periphery network structure by random walkers, Scientific Reports, 3, 1467, 2013. [doi] 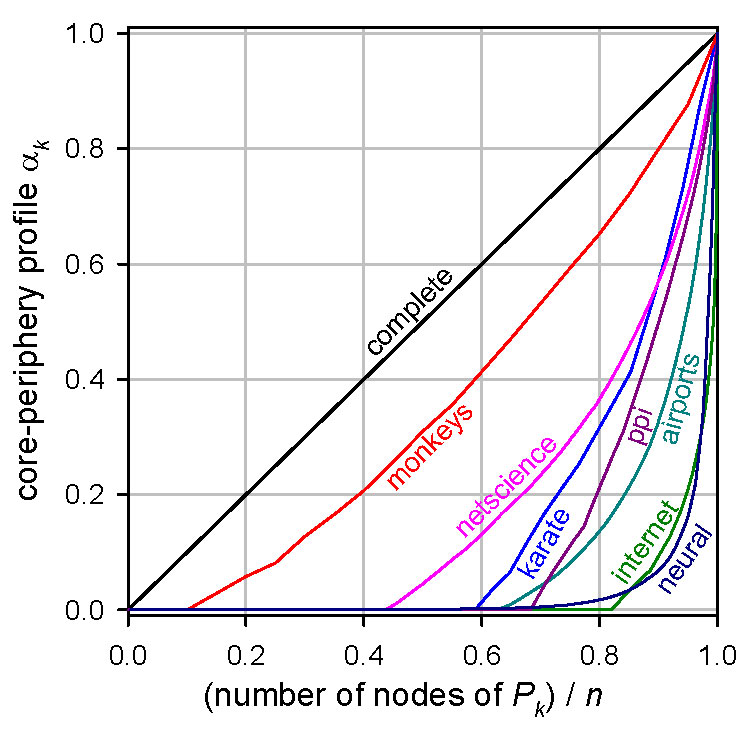
Disclosing the main
features of the structure of a network is
crucial to understand a number of static
and dynamic properties, such as robustness
to failures, spreading dynamics, or
collective behaviours. Among the possible
characterizations, the core-periphery
paradigm models the network as the union
of a dense core with a sparsely connected
periphery, highlighting the role of each
node on the basis of its topological
position. Here we show that the
core-periphery structure can effectively
be profiled by elaborating the behaviour
of a random walker. A curve - the
core-periphery profile - and a numerical
indicator are derived, providing a global
topological portrait. Simultaneously, a
coreness value is attributed to each node,
qualifying its position and role. The
application to social, technological,
economical, and biological
networks reveals the power of this technique in disclosing the overall network structure and the peculiar role of some specific nodes. Matlab code and data used in the paper are available here. |
|
C. Piccardi and L. Tajoli, Existence and significance of communities in the World Trade Web, Physical Review E, 85(6), 066119, 2012. [doi] 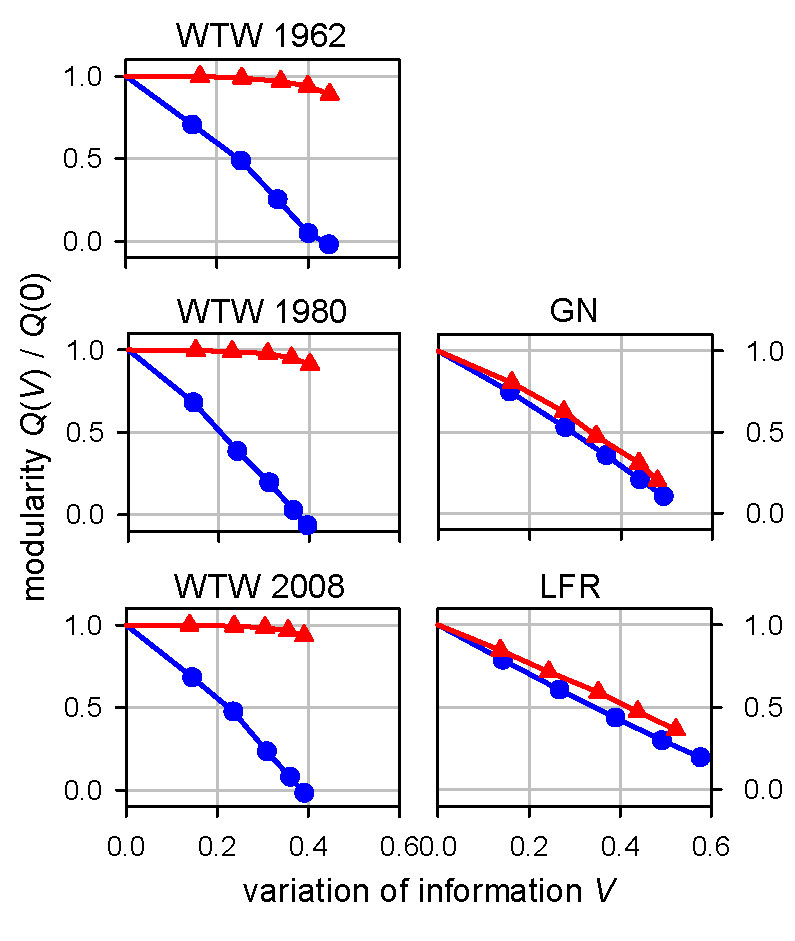 TheWorld
TradeWeb (WTW), which models the
international transactions among
countries, is a fundamental tool for
studying the economics of trade flows,
their evolution over time, and their
implications for a number of phenomena,
including the propagation of economic
shocks among countries. In this respect,
the possible existence of communities is a
key point, because it would imply that
countries are organized in groups of
preferential partners. In this paper, we
use four approaches to analyze communities
in the WTW between 1962 and 2008, based,
respectively, on modularity optimization,
cluster analysis, stability functions, and
persistence probabilities. Overall, the
four methods agree in finding no evidence
of significant partitions. A few weak
communities emerge from the analysis, but
they do not represent secluded groups of
countries, as intercommunity linkages are
also strong, supporting the view of a
truly globalized trading system. TheWorld
TradeWeb (WTW), which models the
international transactions among
countries, is a fundamental tool for
studying the economics of trade flows,
their evolution over time, and their
implications for a number of phenomena,
including the propagation of economic
shocks among countries. In this respect,
the possible existence of communities is a
key point, because it would imply that
countries are organized in groups of
preferential partners. In this paper, we
use four approaches to analyze communities
in the WTW between 1962 and 2008, based,
respectively, on modularity optimization,
cluster analysis, stability functions, and
persistence probabilities. Overall, the
four methods agree in finding no evidence
of significant partitions. A few weak
communities emerge from the analysis, but
they do not represent secluded groups of
countries, as intercommunity linkages are
also strong, supporting the view of a
truly globalized trading system. |
|
C. Piccardi, Finding and testing network communities by lumped Markov chains, PLoS ONE, 6(11), e27028, 2011. [doi] 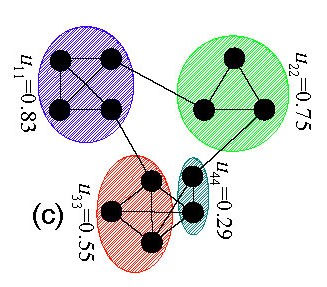 Identifying
communities (or clusters), namely groups of
nodes with comparatively strong internal
connectivity, is a Identifying
communities (or clusters), namely groups of
nodes with comparatively strong internal
connectivity, is afundamental task for deeply understanding the structure and function of a network. Yet, there is a lack of formal criteria for defining communities and for testing their significance. We propose a sharp definition that is based on a quality threshold. By means of a lumped Markov chain model of a random walker, a quality measure called "persistence probability" is associated to a cluster, which is then defined as an "alpha-community" if such a probability is not smaller than a. Consistently, a partition composed of alpha-communities is an "alpha-partition". These definitions turn out to be very effective for finding and testing communities. If a set of candidate partitions is available, setting the desired a-level allows one to immediately select the a-partition with the finest decomposition. Simultaneously, the persistence probabilities quantify the quality of each single community. Given its ability in individually assessing each single cluster, this approach can also disclose single well defined communities even in networks that overall do not possess a definite clusterized structure. Matlab code and data used in the paper are available here. |